

TL;DR
In this article, we'll show you how to set up a continuous data pipeline that seamlessly captures changes from your Postgres database using Change Data Capture (CDC) and streams them to Apache Iceberg. With a simplified approach requiring only a few SQL queries and minimal setup, you can eliminate the need for complex, multi-system architectures.
Real-time Postgres CDC to Iceberg: Why it matters
Postgres is a popular transactional database, but it falls short in meeting analytical requirements, particularly real-time analytics. To address this limitation, Postgres users can leverage Change Data Capture (CDC) to offload data to a data lake, enabling real-time analytical capabilities. By capturing CDC data in real-time and streaming it to Apache Iceberg, users can ensure their data warehouse or lake is always up-to-date, facilitating real-time analytics, machine learning, and informed business decision-making. This approach also enables incremental data loading, reducing latency and overhead associated with batch processing, and ultimately leading to faster data-driven insights, improved operational efficiency, and enhanced customer experiences.
Typical stack
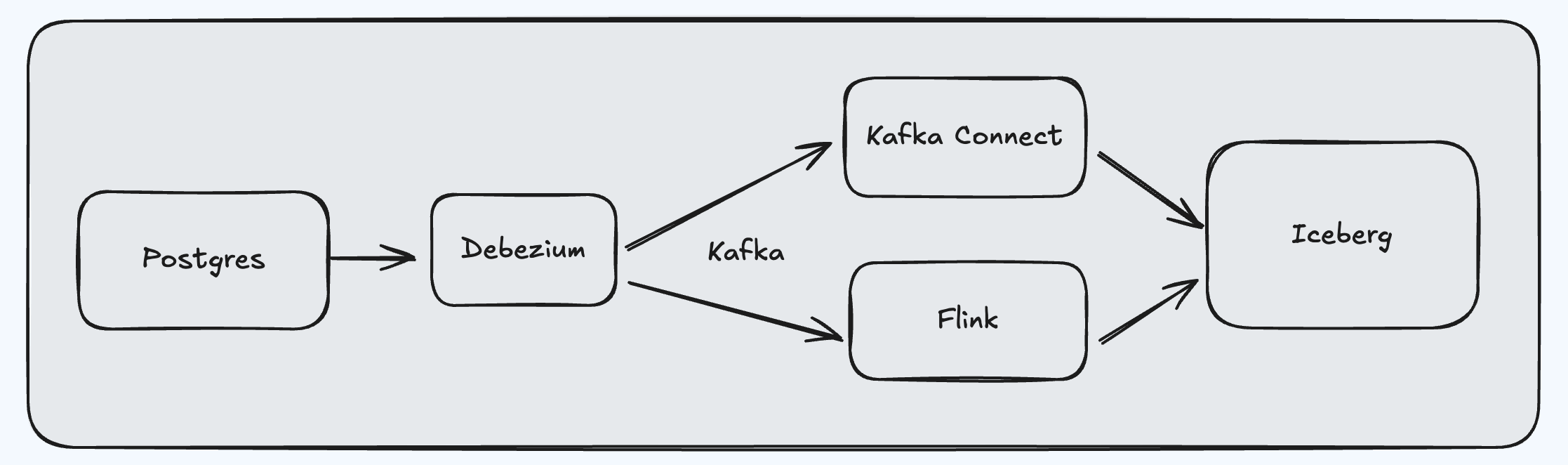
Capturing and syncing database data changes from Postgres to Iceberg normally involves a multi-component stack, including Debezium, Kafka, Kafka Connect, and Flink. This stack works together to capture, transform, and load data into Iceberg. Kafka Connect and Flink then take over, handling data transformation and output to Iceberg. However, managing this complex stack can be challenging. Deploying and configuring Debezium, Kafka, Kafka Connect (or Flink) can be a significant undertaking, which adds complexity to the overall data integration process.
Stack simplified with RisingWave
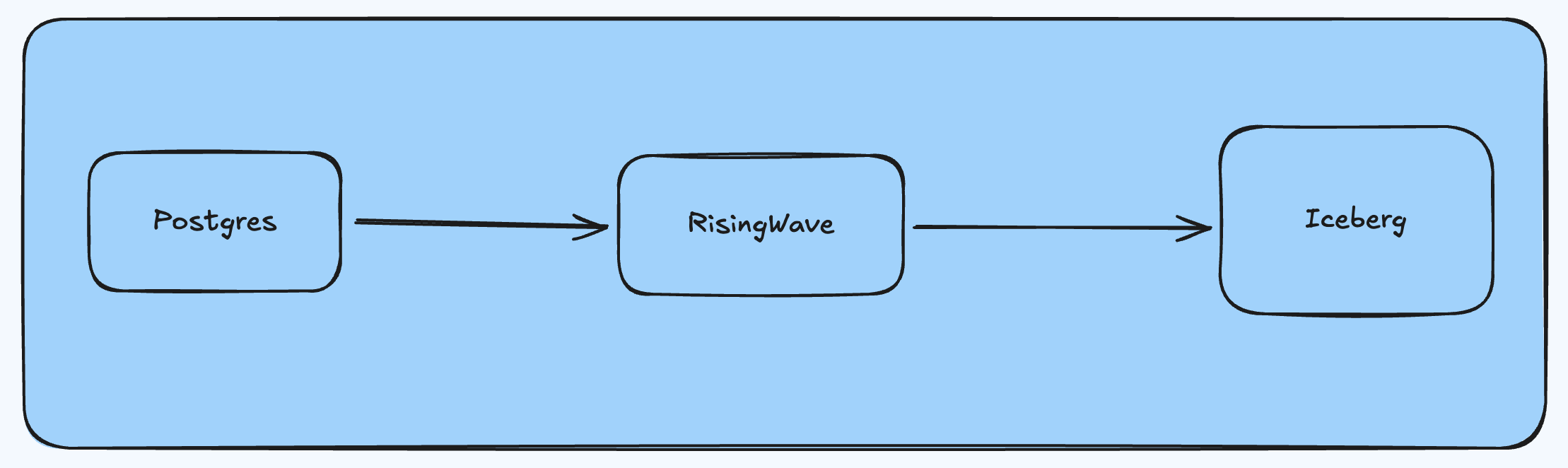
In contrast, RisingWave simplifies this process by providing built-in Postgres source and Iceberg sink connectors, allowing developers to set up a single system (RisingWave) to complete the data pipeline. With RisingWave Cloud, launching a cluster takes just a few minutes, drastically reducing complexity and making it easier to establish real-time data pipelines.
Set up Postgres
To enable CDC on Postgres, you’ll need to configure wal_level to logical, and assign necessary roles and grant necessary privileges to the user. For details, see Set up PostgreSQL .
Let’s create a table in Postgres and insert some data for demonstration purposes.
-- PostgreSQL table
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
customer_id INTEGER NOT NULL,
order_status VARCHAR(20) NOT NULL,
total_amount DECIMAL(10,2) NOT NULL,
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Insert sample data
INSERT INTO orders (customer_id, order_status, total_amount) VALUES
(101, 'pending', 299.99),
(102, 'processing', 1250.50),
(101, 'shipped', 89.99),
(103, 'delivered', 499.99),
(102, 'cancelled', 750.00);
Set up data ingestion in RisingWave
You can start by signing up at RisingWave Cloud and creating a free-tier cluster. Your cluster will be up and running in several minutes.
You can then create a source and then a table in RisingWave. The source will establish a connection to the Postgres instance. The table in RisingWave is mapped to the table in Postgres. It’ll ensure data is persisted in RisingWave. For the same Postgres source, you can create multiple tables in RisingWave. That means you can have multiple CDC pipelines that stream multiple tables into multiple destination systems.
CREATE SOURCE pg_cdc_source WITH (
connector = 'postgres-cdc',
hostname = '127.0.0.1',
port = '8306',
username = 'root',
password = '123456',
database.name = 'mydb',
slot.name = 'mydb_slot'
);
CREATE TABLE orders_rw (
order_id INTEGER PRIMARY KEY,
customer_id INTEGER,
order_status VARCHAR,
total_amount DECIMAL,
last_updated TIMESTAMP,
)
FROM source pg_cdc_source TABLE orders;
Configure the sink connector and transformation logic
To stream data to Iceberg, we'll utilize RisingWave's native Iceberg connector. In RisingWave, a sink is a streaming job that continuously outputs data to a specified destination. This output can be based on a predefined object, such as a table or materialized view, or a custom SELECT query that includes transformation logic.
To illustrate this, let's consider an example CREATE SINK query. In this query, we'll aggregate data from the orders table and output it to Iceberg. We'll use a storage catalog, which stores all metadata in the file system. Note that RisingWave also supports other catalog types, including Hive, REST, Glue, and JDBC.
CREATE SINK orders_status_summary AS
SELECT
order_status,
COUNT(*) as order_count,
SUM(total_amount) as total_revenue,
AVG(total_amount) as avg_order_value,
MIN(last_updated) as first_order_time,
MAX(last_updated) as last_order_time
FROM orders_rw
GROUP BY order_status
WITH (
connector = 'iceberg',
type = 'append-only',
force_append_only = true,
s3.endpoint = '<http://minio-0:9301>',
s3.access.key = 'access_key',
s3.secret.key = 'secret_key',
s3.region = 'ap-southeast-1',
catalog.type = 'storage',
catalog.name = 'demo',
warehouse.path = 's3://icebergdata/demo',
database.name = 's1',
table.name = 't1'
);
Note that you can also output data from orders_rw directly to Iceberg without any transformation. In this case, we’ll use this query instead:
CREATE SINK orders_status_summary
FROM orders_rw
WITH (
connector = 'iceberg',
type = 'append-only',
force_append_only = true,
s3.endpoint = '<http://minio-0:9301>',
s3.access.key = 'access_key',
s3.secret.key = 'secret_key',
s3.region = 'ap-southeast-1',
catalog.type = 'storage',
catalog.name = 'demo',
warehouse.path = 's3://icebergdata/demo',
database.name = 's1',
table.name = 't1'
);
After the stack is set up, you can add, update or delete records to simulate different database updates, and see if the changes are streamed to the Iceberg table.
What’s next?
With RisingWave, you can easily move data from Postgres to Iceberg in real-time. This unlocks new possibilities for real-time analytics and data-driven decision-making. But that’s just the beginning. RisingWave’s robust set of source and sink connectors makes it an ideal choice for complex data pipelines. You can easily integrate data from multiple sources, including databases, messing queues and object storage systems, and send it to multiple destinations, such as data warehouses, lakes, and streaming platforms. Whether you're building a modern data architecture or migrating from a legacy system, RisingWave provides a scalable and reliable solution for your data integration needs.
Try RisingWave Cloud today and start simplifying your data pipelines.
If you would like to stay up to date on what RisingWave is up to, follow us on Twitter and LinkedIn, and join our Slack community to talk to our engineers and hundreds of streaming enthusiasts.