

As companies collect increasing amounts of data daily, it is crucial to query and analyze the data to make timely decisions quickly. To support such business scenarios, OLAP and stream processing are two popular techniques that promise to deliver analytical results with low latency. However, since both techniques claim to target real-time analysis, it can be quite confusing when trying to understand the differences between them and when to use them.
What is OLAP? What is stream processing? How are they different from each other? This blog answers these questions by comprehensively comparing OLAP and stream processing.
What is OLAP?
Online analytical processing, commonly referred to as OLAP, is a summary of systems designed to answer analytical queries over the database swiftly. Traditionally, such a system is known as a data warehouse, which is a centralized repository that stores historical data to be further analyzed.
A typical architecture of deploying OLAP systems is shown in the figure below. OLAP systems usually reside at the end of the data lifecycle. After data are transformed from the data source through the ETL process, clean data are ingested into OLAP systems. Then, OLAP systems answer users’ ad-hoc queries directly and deliver analysis results over the accumulative data in real time.
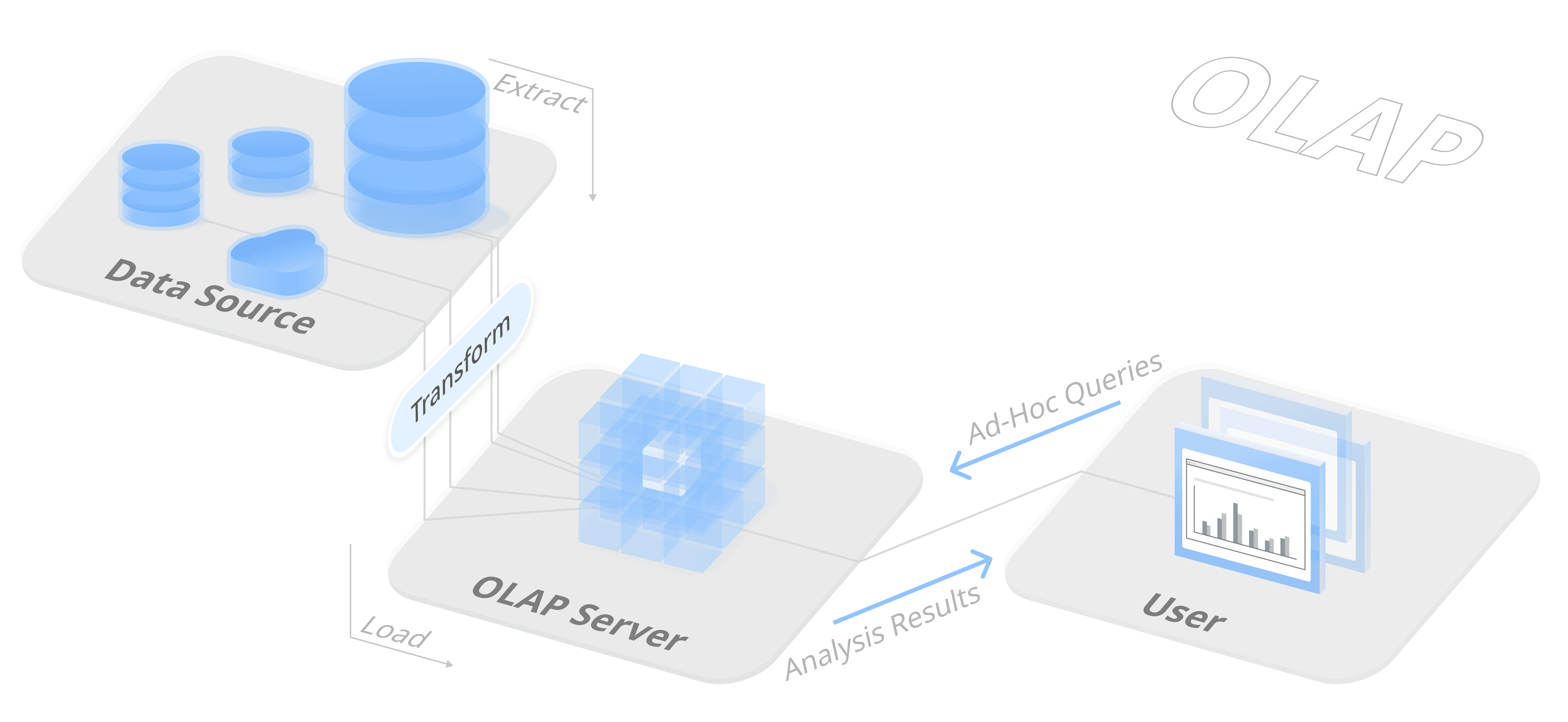
To support real-time query answering, the key technical challenge is to reduce the query latency for complex ad-hoc queries. Historically, OLAP systems relied on data cubes that organize data into multidimensional arrays and extensively use pre-aggregated statistics to answer ad-hoc queries. In modern days, with the development of hardware and cloud computing, the technical trend shifted from data cubes to modern data warehouses, which employ decoupled storage layer, columnar storage format, vectorized query execution, massively parallel processing, and many other techniques. The design principle behind modern data warehouses is to reduce the data loading overhead from the storage layer, fully utilize the computational resources on the cloud via parallelization, and decouple different services to avoid resource wasting.
OLAP systems have been widely deployed to support data analytics and business intelligence. Data scientists and decision-makers can issue their complex and in-depth analytical queries directly on the centralized data repository, and OLAP systems will generate reports to help them gain insights from data and make informed business decisions.
What is stream processing?
Stream processing is a programming paradigm that processes continuous data streams directly after the system receives them. Usually, the stream processing systems do not store the result. Given a pre-defined query, stream processing systems build a streaming pipeline that receives incoming streaming data, processes the stream, and produces an output stream to downstream systems.
The figure below shows that a streaming data architecture comprises multiple components. It starts with a stream source that obtains data from a data producer. Data producers can be sensors, transactional databases, and many other data sources. The stream processing system takes the data streams generated by these producers, transforms the streams, then sinks the output stream to the downstream system, such as an OLAP system. This allows the downstream system to operate over the clean and well-structured data.
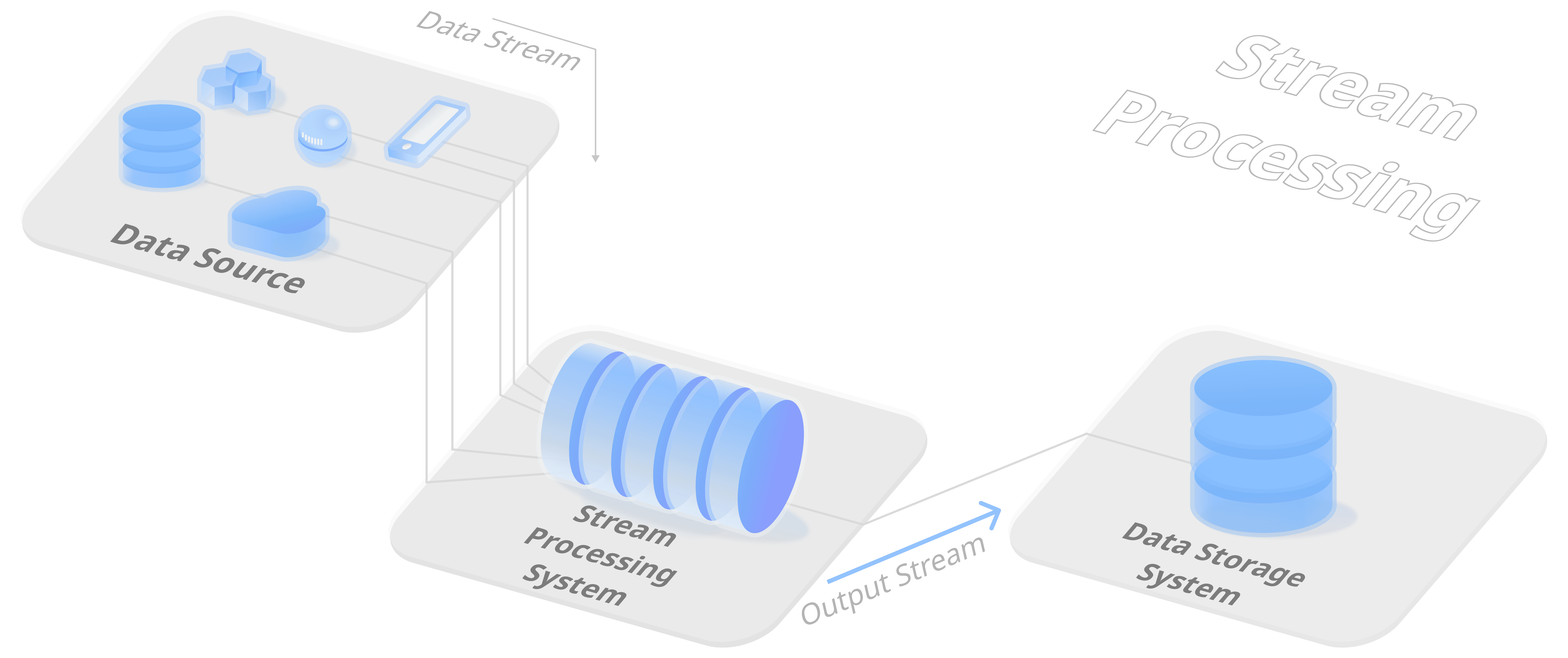
Stream processing systems are designed to give quick updates over a pre-defined query. To achieve that, incremental computation lies at the core of the design principle of stream processing. Instead of rescanning the whole data repository, stream processing systems maintain some intermediate results to compute updates based only on the new data. Such intermediate results are also referred to as states in the system. In most cases, the states are stored in memory to guarantee the low latency of stateful computation. Such a design makes stream processing systems vulnerable to failures. The whole stream processing pipeline will collapse if the state on any node is lost. Hence, stream processing systems use checkpoint mechanisms to periodically back up a consistent snapshot of global states on an external durable storage system. If the system fails, it can roll back to the last checkpoint and recover its state from the durable storage system.
Stream processing is ideal for tasks that need to process data and make decisions on the fly. For example, a fraudulent account must be instantly detected once received by the system, a dirty record must be eliminated before it pollutes the data warehouse, or an alert should be broadcasted immediately once a metric is beyond the threshold. Once users define their queries in advance, the stream processing system can track the query result by incrementally updating it from the newly received data.
How are they different?
While both OLAP and stream processing promises to provide instant analysis results, they differ in a number of ways.
Data source
OLAP systems ingest structured data that are cleaned by other systems. The structured data and cleaned data are gathered to be loaded into the OLAP systems in bulks.
Stream processing systems receive data streams of either raw data or cleaned data. The data streams are generated from upstream message brokers, such as AWS Kinesis or Redis. They consist of events that the message brokers just recorded and continuously delivered to the stream processing systems. Data streams can come from multiple different sources and are continuously collected.
Output
OLAP outputs data analysis results in response to users’ complex ad-hoc queries. The queries are issued over the whole repository, and typically a significant fraction of the repository is relevant to the queries. The query results are often small and can be presented as charts and graphs in business intelligence.
Stream processing outputs data streams that have been queried to be stored in a data sink so they can potentially be further analyzed. The queries are usually simplistic, predefined, and continuously running on data streams to provide cyclical updates. Depending on the use case, the output stream can be either very small or accumulatively very large.
Storage
OLAP systems typically manage their storage in a read-friendly format. Historically, the data for OLAP systems were stored in multidimensional cubes, which pre-aggregates data, making it quick to produce query results. More recently, there has been a shift to columnar databases, which speeds up the querying, sorting, and indexing process, and compresses data better. It is worth mentioning that some OLAP systems do not manage their own storage system, and they read data from an external storage system, in which data are stored in some open formats, such as Apache Parquet or Apache Avro.
Traditionally, stream processing systems do not have self-managed durable storage to be queried. The output streams of data can be saved afterward in a separate system. Instead, states are stored for stateful stream processing, where previous events influence current events. Stream processing systems manage states in different tiers, including local memory, local disks, and external durable storage systems. Modern stream processing systems also started to allow users to issue queries over the managed states directly.
Robustness
OLAP systems generally do not fail because there are not many modifications to the underlying database. If a query fails, the query can be rerun. Creating database backups is still important, but this does not need to be done as frequently as reloading the data is also a recovery method.
On the other hand, stream processing systems often run into failures as they run continuous queries. For stateful streaming, where current events rely on previous events, every single failure in the stream may lead to a global failure. As a result, stream processing systems rely on consistent checkpointing to ensure fault tolerance. This means the metadata of the streaming application is saved. Since stream processing systems are constantly ingesting and analyzing data, there are more opportunities for them to run into failures.
Scale of data
OLAP systems may need to scan through the entire database for a query. This possibly entails processing PB-levels of data.
Stream processing systems continuously process data streams. These systems can handle data streams at speeds up to GBs per second.
Specific use cases
OLAP is widely adapted in business intelligence, for example, in financial reporting, budgeting, and marketing cases. Another important use case is for data scientists to prepare the data to be fed into machine learning models. Data is collected over time in both cases, and a more in-depth, complex analysis is necessary to make decisions that will affect a business long-term.
Stream processing is suitable for fraud detection, sensor data, and ride share matching. These cases are event-driven; data comes in real-time, and instant analysis results are required to make crucial decisions immediately.
Representative systems
OLAP systems include Apache Druid, Apache Pinot, Clickhouse, Redshift, and Snowflake.
Stream processing systems include systems Apache Flink, Apache Storm, and RisingWave.
Purpose in the data journey
OLAP systems are typically used near the end of the data journey after the data has been cleaned and sorted through for relevancy. Users provide complex ad-hoc queries to the system to gain analytical insights based on the data stored in a data warehouse. The analysis results can then be leveraged to make impactful business decisions.
Stream processing systems fit near the beginning of the data life cycle, generally right after the data is generated. With pre-defined queries, the system cleans and provides simple analysis results. The output streams can be stored and analyzed later on with a different system depending on the use case.
| Feature | OLAP | Stream Processing |
| Data Source | Structured and cleaned data in bulk. | Data streams of raw data. |
| Output | Query result of ad-hoc queries over the whole data repository. | Data streams to be processed in downstream systems. |
| Storage | Columnar store, secondary indexes, data cube. Managed centralized storage or external storage. | State store for stateful stream processing. External durable storage for checkpointing. |
| Robustness | Query failure is not an issue. | More vulnerable to failure so it relies on consistent checkpointing. |
| Scale of Data | PB-level accumulative data. | GB-level per second. |
| Use Cases | Business intelligence, data science. | Fraud detection, sensor data, event-driven applications. |
| Representative Systems | Apache Druid, Apache Pinot, ClickHouse, Redshift, Snowflake | Apache Flink, Apache Storm, RisingWave |
| Purpose in the Data Journey | Produces complex analysis results from a data warehouse to answer analytical queries. | Used right after data is generated for quick analysis with pre-defined queries. |
OLAP and stream processing are different sets of techniques suitable for different tasks. While stream processing systems perform pre-defined tasks on incoming data streams in real-time, OLAP systems answer ad-hoc queries over an entire dataset to produce beneficial user insights.
As real-time data analysis becomes the driving force behind numerous fields today, we should choose the most appropriate tools among multiple solutions. Conveniently, there is a trend of merging stream processing and OLAP systems to create a unified engine that makes the entire data analysis process more efficient. We at RisingWave observe this trend and will keep innovating to make real-time data processing simple, affordable, and accessible for all.