

Since last year, Apache Iceberg has been one of the hottest topics in the data infrastructure world.
Databricks recently spent $1 billion to acquire Neon, a startup building a serverless Postgres. Snowflake also spent about $250 million to acquire Crunchy Data, a veteran enterprise-grade Postgres provider.
These are not random acquisitions. They represent a bet by two major database vendors on the same story — Postgres + Apache Iceberg: Postgres for transactional workloads and smaller queries, Iceberg for large-scale analytics, both tied together within the same vendor’s ecosystem.
Postgres and Apache Iceberg are both mature systems, but here’s a question many people haven’t thought through: How do you stream data from Postgres into Apache Iceberg in real time?
It sounds straightforward: just use an existing CDC (Change Data Capture) system like Debezium to write change events directly into Iceberg. But reality is far from that simple.
Here’s the surprising truth: Mainstream systems like Snowflake, Databricks, and Redshift do not natively support “plain CDC writes” into Iceberg.
In this article, I’ll expose the part few people talks about, and explain how RisingWave makes true streaming CDC ingestion into Iceberg possible through a series of engineering techniques.
CDC and the Two Types of Deletes in Iceberg
In OLTP databases like Postgres, changes and deletes happen all the time. An UPDATE is actually implemented as DELETE + INSERT: transparent inside the database, but once you capture the change via CDC, this detail becomes critical.
A CDC event typically includes the table name, primary key, and old/new values — but not the physical location of the row in the downstream system, such as which file and line number it sits in within Iceberg. This means the writer has no direct way to pinpoint the exact physical location of the row to delete.
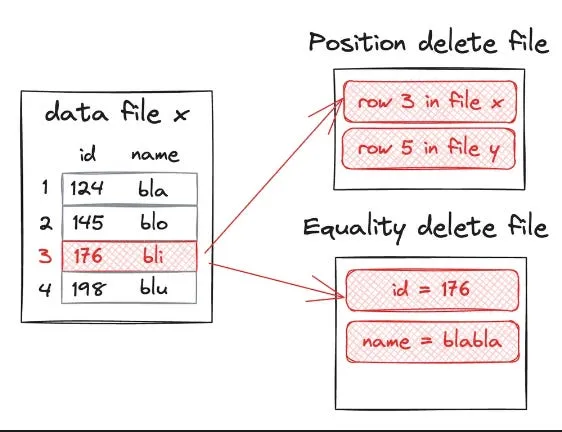
To handle this, Iceberg defines two very different mechanisms for row-level deletes:
Position delete
Deletes by exact file path + row number. The big advantage is high query performance: the query engine just skips the specified rows without having to match values.
But this requires the writer to know the physical location in advance. In batch scenarios, you can scan the table to find this location before deleting. In streaming CDC scenarios, however, you’d need to query Iceberg for the location on every delete: introducing random reads, latency, and drastically lowering throughput under high concurrency. On large tables, real-time performance is essentially impossible.
Equality delete
Deletes by matching column values, typically primary keys. The writer only needs to write the primary key value from the CDC event into an equality delete file — no physical location required.
This is a natural fit for streaming CDC, since tools like Debezium, Kafka Connect, Flink CDC, and RisingWave can generate these files directly.
The downside is that queries must perform merge-on-read: scanning both the data files and the delete files, then filtering out matching rows. If delete files accumulate (very common in high-frequency CDC scenarios), read amplification becomes severe, leading to higher query latency and cost. Periodic compaction is necessary to control this.
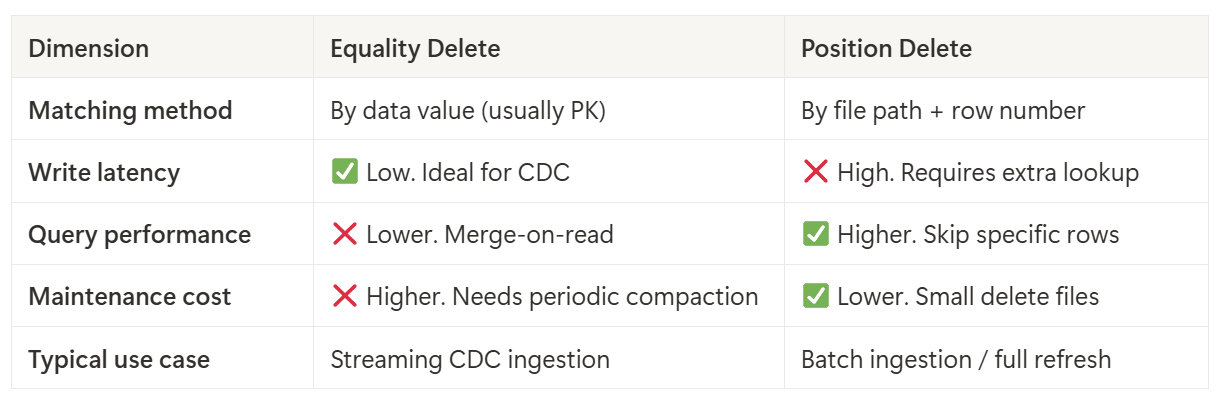
Equality Delete vs. Position Delete: Which to Choose?
Functionally, neither delete type is strictly better — they serve different purposes:
Batch ingestion (e.g., daily full refresh): Scan the data files first to locate the rows to delete, then use position deletes. This gives the best query performance since delete files only store “path + row number,” allowing the query engine to skip rows without value comparisons.
Streaming CDC ingestion (continuous change feed from Postgres/MySQL, etc.): The writer has no access to physical locations, so equality deletes are the only option. This keeps write cost low and latency controlled, but query performance suffers unless you periodically merge equality deletes into data files (or convert them to position deletes) to restore efficiency and cross-engine visibility.
In other words, in streaming CDC scenarios, equality delete is almost the only viable choice — it keeps writes lightweight and low-latency, but puts the cost on the read side with merge-on-read. And here’s the killer: If the downstream engine doesn’t support equality delete, CDC ingestion simply breaks.
Press enter or click to view image in full size
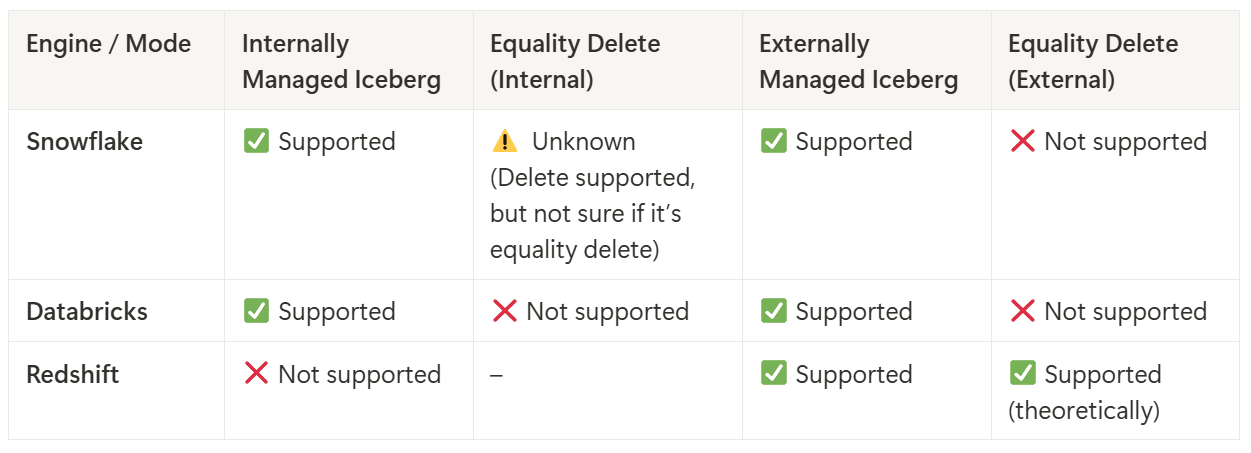
Current State of Equality Delete Support in Query Engines
In streaming CDC ingestion to Iceberg, equality delete is the only realistically viable row-level delete. But Iceberg’s specification is one thing, while actual support by query engines is another, and reality is not as nice as the spec.
Snowflake
Snowflake-managed Iceberg: This mode offers full support for Iceberg tables within Snowflake, including both read and write operations, handled entirely through Snowflake infrastructure.
Externally-managed Iceberg: When Iceberg tables use an external catalog (e.g., AWS Glue), Snowflake provides limited functionality. Notably, only position deletes are supported, and delete-file handling may be incomplete or unreliable.
Databricks
Databricks-managed Iceberg: No support for any row-level deletes (neither equality nor position).
Externally-managed Iceberg: Also no row-level delete support.
In short: Databricks cannot query any delete, no matter whether it’s equality delete or position delete.
Amazon Redshift
Redshift only supports externally managed Iceberg tables (via Glue Catalog), queried through Redshift Spectrum or Serverless. Officially, Iceberg v2 delete files are supported — which includes equality deletes.
Press enter or click to view image in full size
Community Discussions on Equality Delete
In the Iceberg community, there has been ongoing debate about the long-term role of equality deletes. The mailing list has seen proposals like Deprecate Equality Deletes, where some argue that the query performance penalties and implementation complexity may not justify keeping it indefinitely. Another reply showed engineers sharing compromise approaches:
Write equality deletes first for low-latency, high-throughput ingestion.
Periodically convert them to position deletes or merge them into data files to restore query performance and cross-engine compatibility.
Use indexes or Bloom filters to reduce merge-on-read cost at query time.
While the core idea is not to abandon equality delete, the community discussions did acknowledge its unavoidable performance cost and shift that cost from real-time writes to asynchronous maintenance jobs.
From my private conversations with several Iceberg PMC members, it’s clear that full equality delete support across major query engines will be slow — not due to lack of will, but due to complexity. Efficient equality delete reads require engines to simultaneously process multiple file metadata sets, perform cross-file value matching, and push down those filters into a distributed execution plan. That means added complexity at the storage, execution, and file format decoding layers. For query performance–focused systems like Snowflake, Databricks, and Redshift, anything that significantly increases I/O or CPU cost will be adopted very cautiously.
RisingWave’s Solution
RisingWave is the only system today that supports complete, end-to-end architecture for streaming CDC into Apache Iceberg, making it the state-of-the-art solution in this space.
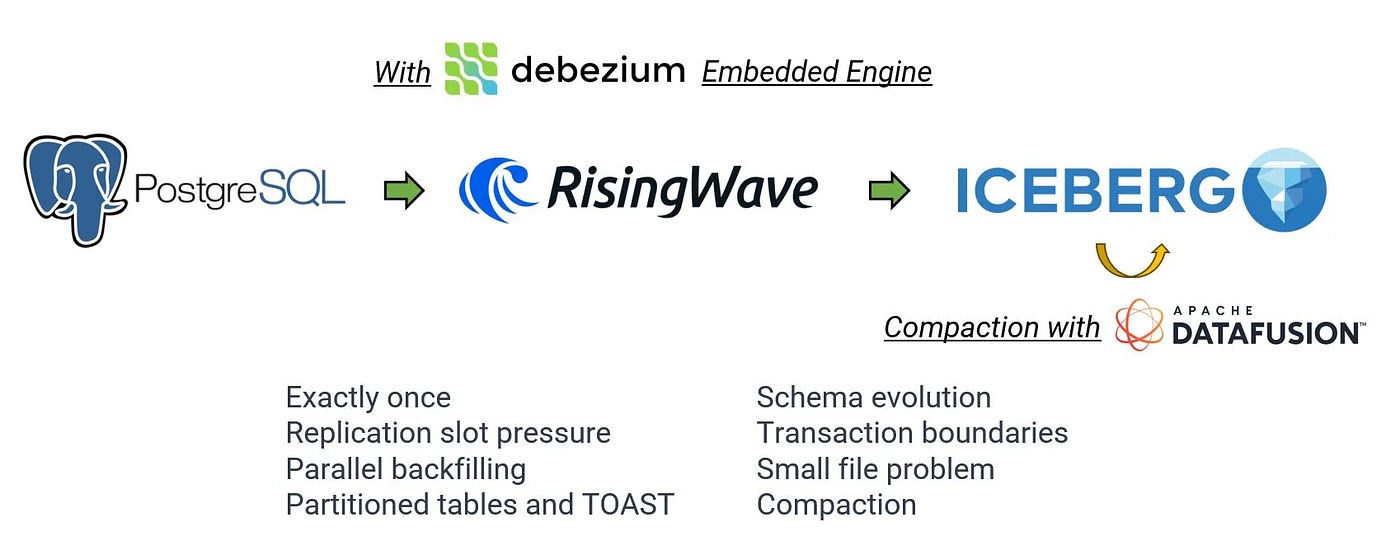
If you’re doing Postgres/MySQL → Apache Iceberg streaming CDC, especially with high-frequency updates and deletes, you’ll quickly find that all existing solutions stumble at delete handling. The problem isn’t writing data — it’s the equality vs. position delete choice.
As discussed earlier, in CDC scenarios, equality delete is the only realistic option. It keeps writes lightweight and low-latency, but query engines must pay the merge-on-read cost. Worse, many mainstream engines — Snowflake, Databricks, Redshift — don’t support equality delete at all, meaning those deletes won’t be honored.
RisingWave addresses this with an end-to-end CDC-to-Iceberg pipeline built around:
Write Phase: Optimized for High-Frequency Updates and Deletes
In CDC scenarios, high-frequency updates and deletes inevitably generate large numbers of Delete Delete files. RisingWave maximizes efficiency on the write path by combining different deletion strategies:
Primary keys updated multiple times within the same batch: Since their physical locations are already known within the batch, RisingWave uses the more efficient Position Delete to remove the target rows, avoiding extra matching overhead.
Updates or deletes for primary keys outside the current batch: RisingWave skips expensive physical location lookups and instead generates Equality Delete files directly based on the primary key (for sources such as Postgres, MySQL, MongoDB, SQL Server, etc.).
This hybrid approach leverages the high performance of position deletes for in-batch updates and the flexibility of equality deletes for out-of-batch changes. It maintains both low latency and high throughput in high-concurrency scenarios while avoiding the random I/O and latency costs of real-time position lookups.
Compaction Phase: Schedulable Compaction (Data Merging)
Large numbers of Equality Delete files can cause significant read amplification, as query engines must scan both data files and delete files and perform value matching. RisingWave internally implements a schedulable compaction service (see https://github.com/nimtable/iceberg-compaction, an engine based on DataFusion project) that periodically removes equality delete files and compacts small files, reducing read amplification and storage fragmentation while preserving data freshness:
Low-latency mode: Shorten the compaction interval (controlled by the
Commit Checkpoint Interval, default 1 minute) to keep data nearly real-time visible, even if the number of delete files temporarily increases.Offline analytics mode: Extend the compaction interval to reduce file creation frequency, S3 API call costs, and the number of small files.
Planned future optimizations include:
Partial Compaction: Limit merge scope based on key ranges to reduce unnecessary data scanning.
Optimizing Extra Large Single-Table Compactions: Use more efficient task splitting and multi-node parallelism to accelerate compaction for TB/PB-scale large tables.
Export Phase: Cross-Engine Compatibility Handling
External-table modes in Snowflake, Databricks, and Redshift generally do not support or cannot reliably interpret Equality Delete files. To address this compatibility gap, RisingWave runs targeted compaction before export to produce a “clean” version with no delete files:
Internal real-time queries can continue using the equality-delete version to maintain low latency.
Cross-platform analytics can query the clean version, ensuring compatibility with engines that do not support equality deletes.
Exactly-Once and Idempotency Guarantees
Unlike Flink CDC’s open-source Iceberg connector or Kafka Connect’s two-phase commit (complex and performance-heavy), RisingWave’s custom logstore provides idempotent commits:
All commits are replayable and verifiable, preventing duplicate writes or data loss.
The performance overhead is minimal, making it well-suited for high-frequency update/delete scenarios in real-time ingestion pipelines.
Successful Stories
Siemens is an enterprise Snowflake customer that needs to stream large volumes of high-concurrency business data into Apache Iceberg for analytics in Snowflake.
Before adopting RisingWave, their process looked like this:
Real-time CDC data was written directly into Iceberg, with all deletes materialized as Equality Delete files.
Since Snowflake external tables do not support reading equality deletes, Siemens had to periodically run a Spark job to remove all delete files (effectively performing a full compaction).
Only after the delete files were cleared could Snowflake read the data correctly.
This approach added latency and compute costs from running Spark jobs, reduced real-time visibility, and increased architectural complexity.
After adopting RisingWave, Siemens switched to a hybrid delete strategy: position deletes for primary keys updated multiple times within the same batch, and equality deletes for updates/deletes outside the batch.
RisingWave’s built-in schedulable compaction automatically removes equality delete files and merges small files at the right time:
Internal real-time queries (e.g., risk control or monitoring systems) can query Iceberg tables containing both equality deletes and position deletes, getting second-level freshness.
Snowflake external tables read a “clean” version exported by RisingWave, eliminating the need for separate Spark cleanup jobs and avoiding all equality delete compatibility issues.
This transformation reduced data availability latency from batch-level to real-time, simplified the architecture, cut operational overhead, and preserved full compatibility with Siemens’s existing BI tools.
Conclusion
In recent years, Postgres + Apache Iceberg has evolved from a technical discussion point into a strategic bet for companies like Databricks, Snowflake, and Redshift. But when you actually implement CDC ingestion, reality hits hard — especially around change and delete handling.
Mainstream engines have inconsistent equality delete support, and poor cross-platform compatibility turns “streaming Postgres to Iceberg” into a minefield.
RisingWave’s approach is pragmatic: avoid unnecessary complexity in the write path, embrace equality delete as the efficient CDC option, and then use controllable compaction and pre-export optimization to solve the query performance and compatibility issues at the right time. This keeps the write side light and fast, while allowing the read side to get a clean, delete-free version when needed.
It’s an engineering trade-off — not about theoretical perfection, but about building a CDC-to-Iceberg system that runs stably in production, with predictable latency and transparent costs. In other words, we’re not just building a “faster CDC tool,” we’re building a CDC ingestion system that can actually run for the long haul in real-world workloads.