
RisingWave vs Apache Flink: Which Streaming Platform Should You Choose?
RisingWave is a PostgreSQL-compatible streaming database that uses SQL instead of Java, with up to 10x lower infrastructure cost than Flink. Compare architecture, performance, cost, and ease of use.

Why is RisingWave easier to use than Apache Flink?

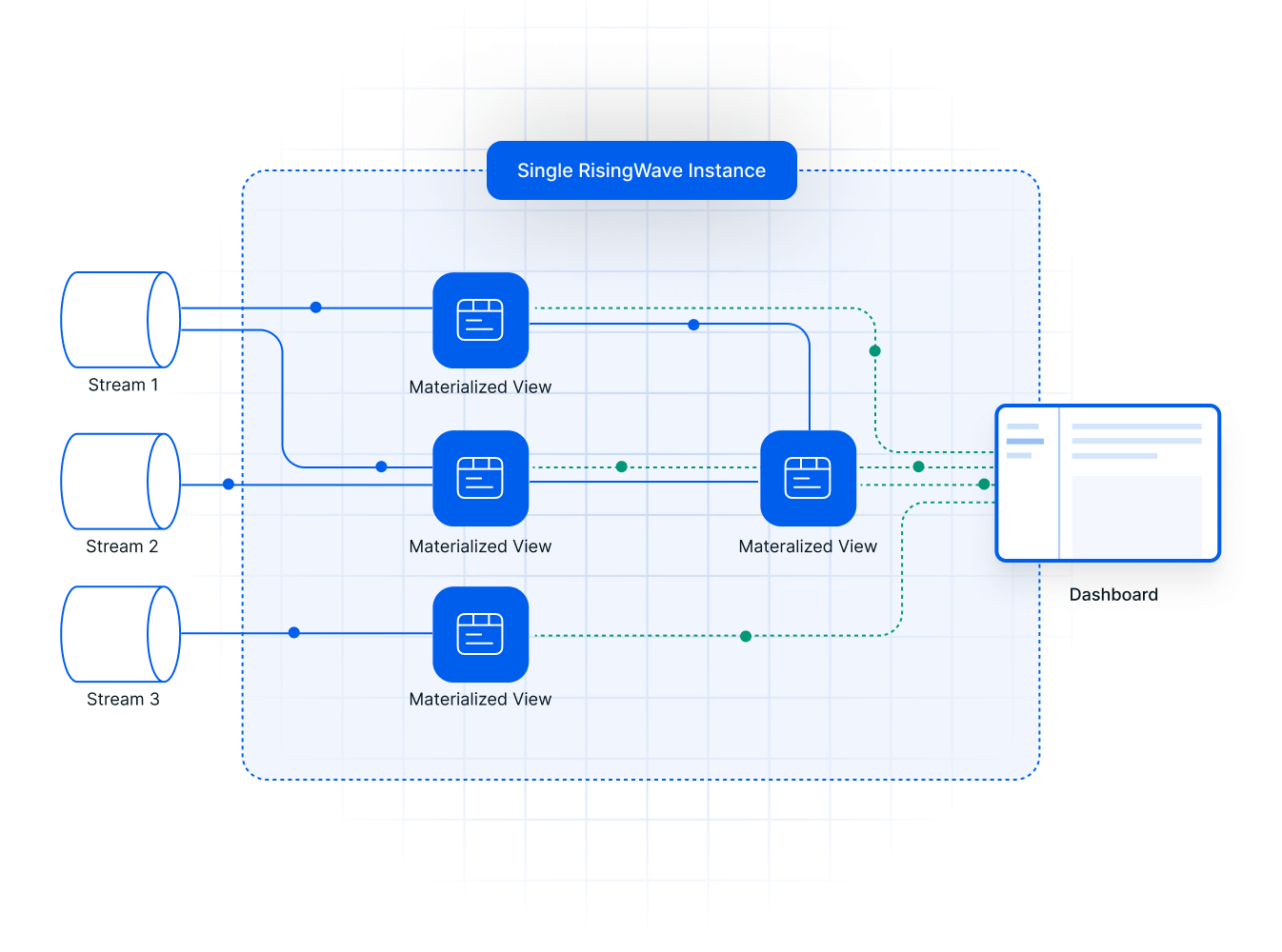

How does RisingWave simplify streaming architecture compared to Flink?
RisingWave unifies stream processing and data serving in a single system, eliminating the need for separate serving databases that Flink deployments require.
Flink specializes in stream processing, but it relies on other datastores for serving real-time data, which may not be optimized for that purpose. In contrast, RisingWave is built on a unified batch and stream processing architecture with a built-in serving layer. This enables data processing within a single framework, reducing both complexity and cost.
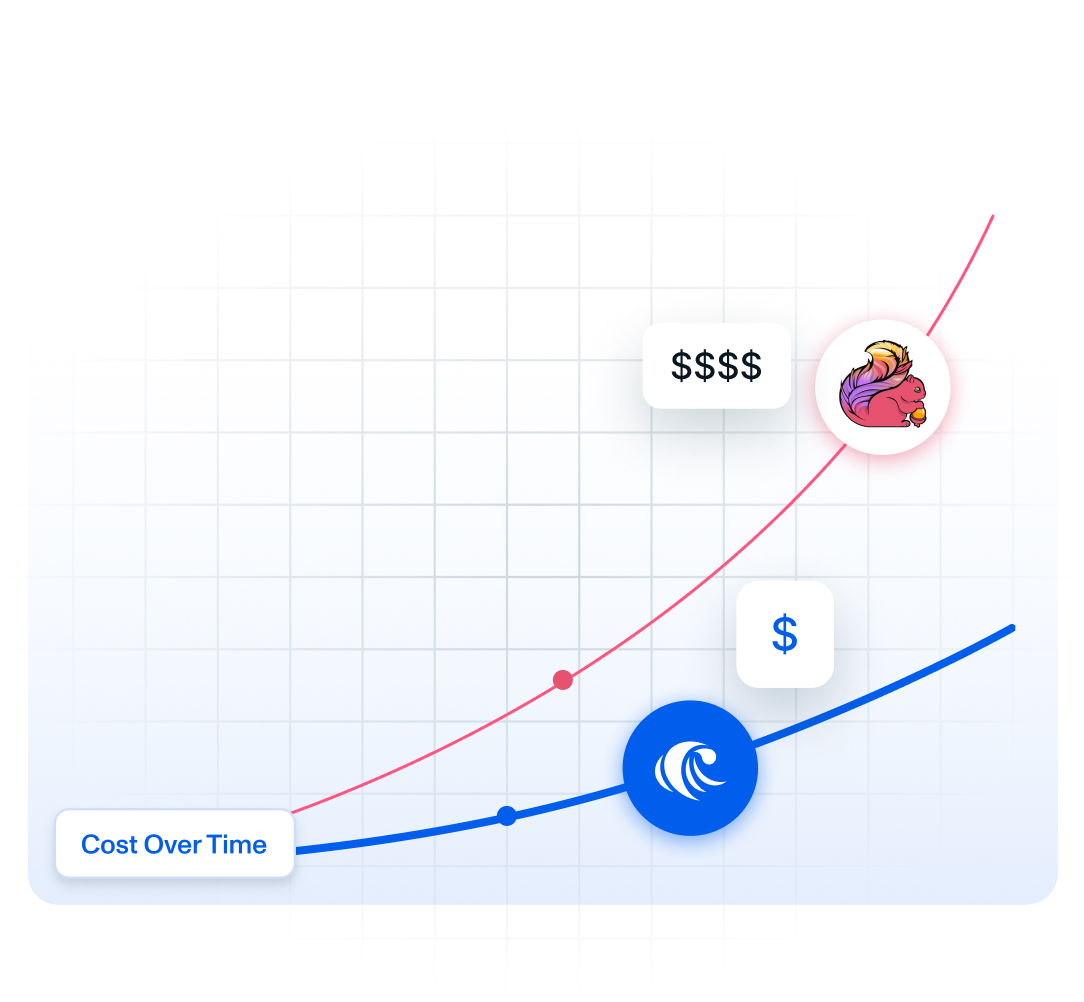
How much cheaper is RisingWave compared to Apache Flink?
RisingWave delivers up to 10x cost efficiency over Flink by using S3-compatible object storage instead of provisioned local SSDs, scaling compute resources dynamically in seconds, and eliminating JVM overhead.
RisingWave was created during the cloud era. By adopting a modern decoupled compute and storage architecture.
 RisingWave achieves better elasticity and cost efficiency. In particular RisingWave persists its data in S3 or other compatible cloud storage services.
RisingWave achieves better elasticity and cost efficiency. In particular RisingWave persists its data in S3 or other compatible cloud storage services.- RisingWave can handle complex streaming joins over large time windows and recover from failures in seconds, not minutes or hours.
- The new architecture also allows each component to be optimized separately, reducing resource waste and avoiding task overload.
However, this very architecture can give rise to concerns regarding execution costs. Due to the nature of its local state storage, e.g. RocksDB, Flink needs to scale large enough to handle large streaming joins and other stateful stream processing tasks.
However, this very architecture can give rise to concerns regarding execution costs. Due to the nature of its local state storage, e.g. RocksDB, Flink needs to scale large enough to handle large streaming joins and other stateful stream processing tasks.
Read More
How does RisingWave compare to Apache Flink?
| RisingWave | Apache Flink | |
|---|---|---|
| License | Apache License 2.0 | Apache License 2.0 |
| System category | Streaming database | Stream processors |
| Architecture | Cloud-native Decoupled compute-storage | MapReduce-style Coupled compute-storage |
| Programming API | SQL + UDF (Python, Java, and more) | Java, Scala, Python, SQL |
| Client libraries | Java, Python, Node.js, and more | - |
| State management | Native storage persisted in S3 or equivalent storage | RocksDB in local machine; periodically checkpointed to S3 |
| Query serving | Support concurrent ad-hoc SQL query serving | Support batch mode execution |
| Correctness | Support exactly-once semantics, out-of-order processing, snapshot read, and consistent read | Support exactly-once semantics and out-of-order processing |
| Integrations and tooling | Big-data ecosystem, cloud ecosystem, and PostgreSQL ecosystem | Big-data ecosystem |
| Learning curve | Extremely shallow (PostgreSQL-Like experience) | Steep (Flink-specific interface) |
| Failure recovery | Instant | Minutes to hours (depending on specific system configuration) |
| Dynamic scaling | Transparent and instant | Stop the world |
| Performance cost | Low (especially when handling complex queries like joins) | High |
| Typical use cases | Streaming ETL, streaming analytics, online serving | Streaming ETL, streaming analytics |
| License | Apache License 2.0 |
| System category | Streaming database |
| Architecture | Cloud-native Decoupled compute-storage |
| Programming API | SQL + UDF (Python, Java, and more) |
| Client libraries | Java, Python, Node.js, and more |
| State management | Native storage persisted in S3 or equivalent storage |
| Query serving | Support concurrent ad-hoc SQL query serving |
| Correctness | Support exactly-once semantics, out-of-order processing, snapshot read, and consistent read |
| Integrations and tooling | Big-data ecosystem, cloud ecosystem, and PostgreSQL ecosystem |
| Learning curve | Extremely shallow (PostgreSQL-Like experience) |
| Failure recovery | Instant |
| Dynamic scaling | Transparent and instant |
| Performance cost | Low (especially when handling complex queries like joins) |
| Typical use cases | Streaming ETL, streaming analytics, online serving |
Frequently Asked Questions
Common questions about choosing between RisingWave and Apache Flink