

As a developer advocate at RisingWave Labs, I often encounter confusion about the differences between streaming databases like RisingWave and time-series databases (TSDBs). Both handle high-velocity data, but their strengths lie in distinct areas. This post clarifies these differences, contrasting streaming databases (with RisingWave as an example) with popular TSDBs like InfluxDB, Prometheus, and TimescaleDB to help you choose the right tool for your real-time data needs.
Disclaimer: As a developer advocate for RisingWave Labs, I have a natural inclination towards streaming databases. However, this post aims to provide a balanced comparison between TSDBs and streaming databases to help you make an informed decision based on your specific requirements.
TL;DR
Choose a TSDB if you need:
Storage and retrieval of raw time-series data.
Ad-hoc queries to analyze historical trends over extended periods.
Choose a streaming database like RisingWave if you need:
Real-time processing of continuous event streams.
Results of predefined metrics with a latency of hundreds of milliseconds.
Pre-storage data processing with complex transformations like multi-way joins, aggregations, and window functions.
Time-Series Data vs. Event Streaming Data: Understanding the Core Differences
The fundamental difference between TSDBs and streaming databases lies in the nature of the data they handle:
| Feature | Time-Series Data (TSDBs) | Event Streaming Data (Streaming DBs) |
| Nature | Regular, time-ordered data points | Discrete, potentially irregular events |
| Schema | Usually fixed, predictable | Often flexible, can vary per event |
| Arrival | Typically at fixed intervals (e.g., every minute) | Triggered by events, can be irregular |
| Examples | Sensor readings (temperature, humidity), stock prices, CPU usage | User actions (clicks, purchases), system events (logins, errors), financial transactions |
| Focus | Storing and querying historical trends | Processing and analyzing data in motion |
| Typical query | What was the average temperature over the past week? | How many users have signed up in the last 5 minutes? |
| Typical fields | timestamp (string), sensor_id (string), value (number), unit (string) | event_id (string), event_type (string), timestamp (string), user_id (string), ... (other fields vary by event type) |
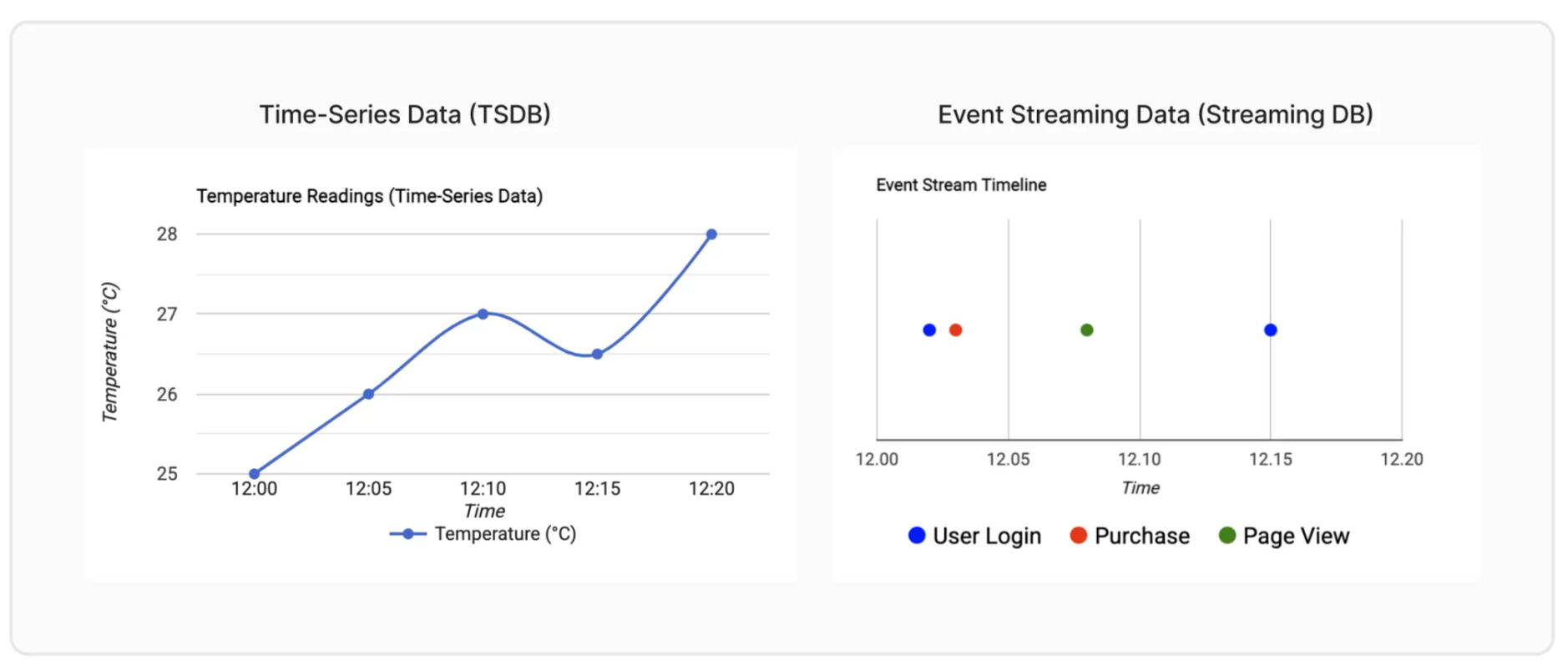
TSDBs excel at storing and analyzing historical trends, following a "store-then-analyze" approach. Streaming databases, on the other hand, process data as it arrives ("data in motion"), enabling real-time insights and actions. A key feature of streaming databases is their ability to join real-time streams with historical data residing in tables.
Architectural Role: Destination vs. Engine
TSDBs and streaming databases play distinct roles in a data architecture:
TSDBs as Destinations: TSDBs are optimized for storing and analyzing historical time-series data. They are the destination where data is stored for later analysis of trends and patterns. Think of analyzing long-term stock market trends – a TSDB is ideal for this.
Streaming Databases as Engines: Streaming databases like RisingWave act as the engine of real-time data pipelines. They ingest, process, and transform continuous data streams to power real-time analytics and event-driven applications. While they can store processed data (materialized views), they often feed data lakes or data warehouses for long-term storage.
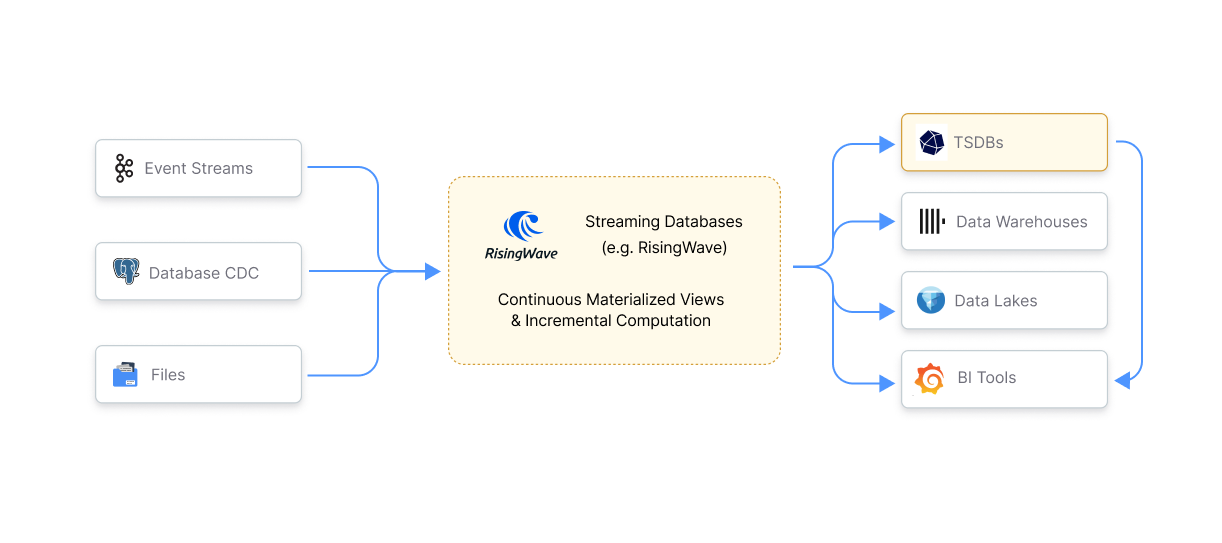
Query Patterns: Ad-hoc vs. Continuous
TSDBs are optimized for ad-hoc queries and time-range scans over historical data. Example: "What was the average CPU usage over the past month?"
Streaming Databases are designed for continuous*,* predefined queries over streaming data. These queries, often called streaming jobs, are defined upfront and run continuously, updating results as new data arrives. For example, in RisingWave, you could create a materialized view to track the number of user signups per minute:
CREATE MATERIALIZED VIEW signup_rate AS
SELECT COUNT(*) FROM users WHERE signup_time > now() - interval '1 minute';
This materialized view will continuously update, always providing the latest count of signups in the last minute.
Data Retention: Policies vs. Temporal Filters
TSDBs: Use retention policies to manage data. These policies define how long data is stored before automatic deletion (e.g., "keep data for 30 days").
Streaming Databases: Often use temporal filters within streaming jobs to process only the most recent data. These filters define a time window for processing (e.g., "process data from the last hour"). In RisingWave, you could use a temporal filter like WHERE event_time > NOW() - INTERVAL '1 hour' to process only data from the last hour.
Integration Pattern: Pull-based vs. Event-driven
TSDBs typically follow a pull-based integration pattern. Downstream systems, such as BI tools or analytical applications, are responsible for initiating queries to retrieve data from the TSDB. For instance, a dashboarding tool might periodically query a TSDB to fetch the latest metrics for visualization.
Streaming databases, in addition to the pull-based integration pattern, can also employ an event-driven integration pattern. They can proactively push new data or updates to downstream systems as soon as they are available. This is commonly achieved through streaming the results to messaging queues or using WebSockets. For example, RisingWave can act as a source for messaging queues like Apache Kafka, publishing processed data or change events to Kafka topics, which downstream systems can then subscribe to.
Ecosystem: Monitoring vs. Real-time Pipelines
TSDBs are tightly integrated with the monitoring and observability ecosystem. They often work with data collection agents, monitoring systems, visualization tools, and alerting systems to provide a comprehensive view of system health and performance.
Streaming Databases are key components of real-time data processing pipelines. They integrate with streaming platforms (like Kafka), operational databases, data warehouses/lakes, and BI tools to enable real-time analytics and event-driven applications.
Use Cases and Synergy: Combining the Power of TSDBs and Streaming Databases
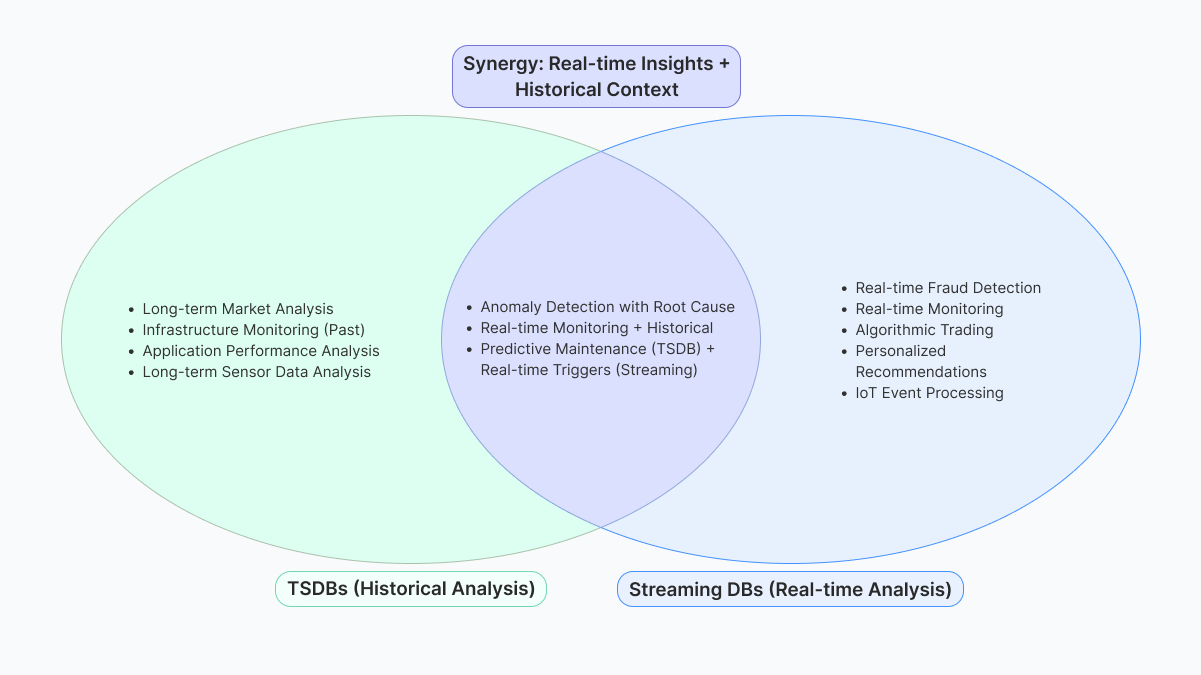
TSDBs and streaming databases excel in different areas:
TSDBs are ideal for historical analysis. Common use cases include:
Historical Market Analysis: Studying historical trends in stock prices.
Infrastructure Monitoring: Analyzing historical performance data to optimize resource utilization.
Streaming Databases are designed for real-time analytics and event-driven actions. They are well-suited for:
Fraud Detection: Identifying fraudulent transactions as they occur.
Real-time Monitoring and Market Analysis: Tracking key metrics with up-to-the-second dashboards for financial markets and other industries.
Working Together
While distinct, TSDBs and streaming databases can be used together effectively. A common pattern is to use a streaming database for real-time processing and then store the aggregated data in a TSDB for long-term historical analysis. For instance, a system could use a streaming database to detect anomalies and trigger alerts, while simultaneously sending data to a TSDB to identify the root cause later.
Future Trends
The lines between TSDBs and streaming databases are becoming increasingly blurred. We're seeing a convergence of capabilities, with some TSDBs adding streaming features and vice-versa. This trend reflects the growing need for systems that can handle both real-time and historical data. The rise of cloud-native architectures, serverless deployments, and the increasing use of stream processing for AI are further accelerating this evolution.
Wrapping up
This comparison highlights the key differences between TSDBs and streaming databases. Choosing the right tool depends on your specific needs, particularly whether you need to analyze historical trends or react to events in real-time. If you're curious about streaming databases, explore RisingWave – it's open-source, and you can find more resources and tutorials on our website and community!