

Data lake compaction refers to the process of combining many small data files into larger, more manageable files within a data lake. This compaction reduces file counts, which helps systems handle data more efficiently. High numbers of small files can slow down performance and increase resource use. By organizing data through compaction, organizations achieve faster query times and lower storage costs. Data lake compaction plays a key role in maintaining system health and ensuring that data remains accessible and ready for analysis.
Key Takeaways
Data lake compaction combines many small files into larger ones to speed up queries and reduce storage costs.
Small file compaction lowers memory use and metadata overhead, helping systems run faster and handle more data efficiently.
Techniques like bin packing and sorting improve file organization, while formats like Parquet support better compression and query performance.
Delta Lake optimize automates compaction safely, improving query speed and reducing manual work for both batch and streaming data.
Regular compaction keeps data lakes scalable, cost-effective, and compliant by removing stale data and improving resource use.
Data Lake Compaction
Small File Compaction
The small file problem remains a persistent challenge in modern data lakes. Many industries experience rapid growth in the number of tiny files due to frequent data ingestion and event tracking. IoT applications, for example, generate thousands of sensor readings every minute, resulting in countless small files. Retail businesses also contribute to this issue by recording sales events at multiple locations, producing millions of small JSON files daily. Streaming ingestion and micro-batching further amplify the small file problem, especially when cloud object storage like S3, which favors large objects, is used.
Small file compaction addresses this challenge by consolidating numerous tiny files into fewer, larger files. This process reduces the total file count, making data management more efficient and improving system scalability. Apache Iceberg and similar platforms create new metadata and delta files for every update, insert, or delete operation. Frequent small batch uploads and derived datasets from processing engines also contribute to file proliferation. By applying small file compaction, organizations minimize metadata overhead and optimize query performance.
Small file compaction reduces metadata memory consumption on servers. JuiceFS, for instance, compresses idle directories and uses compact memory formats, lowering average metadata size per file from nearly 600 bytes to about 50 bytes. This efficiency allows systems to handle more files with the same hardware resources. The following table illustrates the impact of file count on metadata memory requirements:
| Scenario | File Count | File Size | Metadata Memory Calculation | Total Metadata Memory (Bytes) |
| 1 | 1 | 192 MiB | 150 x (1 inode + (2 blocks x 3 replication)) | 1,050 |
| 2 | 192 | 1 MiB | 150 x (192 inodes + (192 blocks x 3 replication)) | 115,200 |
A high number of small files increases memory consumption, slows down server restarts, and raises latency in distributed storage systems. Small file compaction streamlines metadata operations, reduces disk seeks, and improves task scheduling in frameworks like Spark and MapReduce.
Compaction Techniques
Data lake compaction relies on several technical strategies to optimize file layout and query performance. Bin packing combines files to reach a target size quickly, without sorting, making it ideal for frequent compactions that resolve the small file problem. Sort strategies merge and organize data by key, enhancing read performance for queries that filter on specific columns. Z-order strategies interleave multiple columns, supporting multi-dimensional sorting for complex queries, though they require more computational resources.
Parquet and ORC, as columnar formats, support advanced compression, predicate pushdown, and selective column reads. These features improve compaction by reducing storage size and query scan overhead.
Avro, a row-based format, offers schema evolution and high throughput for write-heavy workloads but lacks efficient compression and predicate pushdown, limiting compaction effectiveness.
Parquet supports automatic schema merging, which helps manage evolving datasets during compaction.
Merging delete files during compaction is essential for maintaining data consistency and optimizing query performance. In Merge-on-Read systems like Apache Iceberg and Apache Hudi, compaction merges accumulated delete files with base data files. This process ensures that deleted or stale rows are properly invalidated, reducing the overhead of merging multiple small delete files at read time. Hudi’s incremental compaction at the file group level limits the data scanned and merged during queries, improving efficiency.
Apache Paimon uses deletion vectors to mark invalidated rows, masking stale data and ensuring consistency. These vectors are applied when rewriting data files into larger files, removing deleted rows and reducing read amplification. Readers skip stale data efficiently, which improves query performance.
Frequent compaction operations, such as enabling Delta Lake's Auto-optimize and Auto-compaction features, consolidate small files into larger blocks, typically around 128MB. This minimizes fragmentation, improves read performance, and reduces storage overhead. Regular use of the OPTIMIZE command maintains optimal file sizes and data layout, enhancing performance and cost efficiency. Infrequent compaction leads to slower queries, increased storage costs, and higher operational expenses due to complex file management.
Effective data lake compaction lowers hardware requirements, reduces energy consumption, and simplifies maintenance. Real-world cases show storage cost reductions of up to 30% and improved data processing speeds by 25% due to efficient compaction.
Data lake compaction balances real-time ingestion needs with efficient queries by minimizing file count and metadata operations. The choice of data format, compaction strategy, and frequency of operations directly influences the effectiveness of small file compaction and overall data lake performance.
Performance and Efficiency
Query Speed
Compaction directly impacts the performance of data lakes by improving the speed of queries. When a system contains thousands of small files, each query must scan and process more metadata and file handles. This overhead slows down data queries and increases latency. By merging small files into larger, well-organized files, compaction reduces the number of files that query engines must access. As a result, queries run faster and more efficiently.
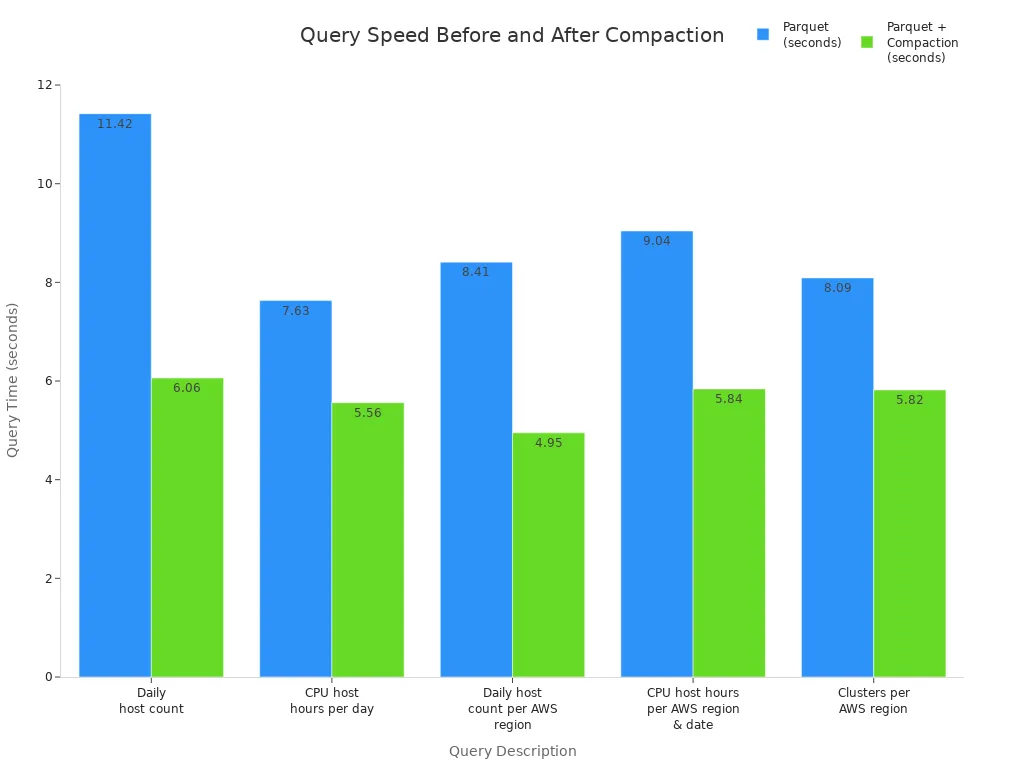
A case study on Delta Lake Auto Compaction demonstrated a 66% improvement in query speeds after compaction. Benchmarks using Athena and Upsolver also show that compaction can boost query performance by 27% to 47% compared to using Parquet files without compaction. The following table highlights these improvements:
| Query Description | Raw CSV (seconds) | Parquet (seconds) | Parquet + Compaction (seconds) | Improvement from Parquet to Parquet + Compaction |
| Daily host count | 16.15 | 11.42 | 6.06 | ~47% faster |
| CPU host hours per day | 13.72 | 7.63 | 5.56 | ~27% faster |
| Daily host count per AWS region | 18.13 | 8.41 | 4.95 | ~41% faster |
| CPU host hours per AWS region/date | 17.33 | 9.04 | 5.84 | ~35% faster |
| Clusters per AWS region | 16.23 | 8.09 | 5.82 | ~28% faster |
Compaction not only accelerates queries but also reduces metadata overhead. Fewer files mean less metadata for the system to track, which leads to faster metadata operations and improved overall performance optimization.
Resource Utilization
Efficient compaction enhances resource utilization in large-scale data lakes. By reducing file counts, systems use less memory for metadata and require fewer disk seeks during queries. This efficiency supports better scalability and lowers operational costs. Automated frameworks like AutoComp and Apache Hudi dynamically adjust file sizes, preventing small file proliferation and maintaining optimal file organization without manual intervention.
However, compaction introduces trade-offs. Merging files demands significant compute resources, especially in petabyte-scale environments. Systems like Apache Iceberg may require powerful clusters for compaction tasks, sometimes doubling resource needs compared to other solutions. Streaming workloads must balance low-latency data ingestion with the need for efficient file sizes. Right-sizing clusters becomes critical, as adding more resources does not always yield proportional performance gains.
Monitoring tools such as LakeView and Table Optimizer help teams track compaction events, analyze performance metrics, and optimize resource allocation. These tools provide dashboards, alerts, and automated reports, enabling continuous performance monitoring and efficient data management.
Effective compaction strategies ensure that data lakes remain scalable, cost-effective, and ready to handle demanding data queries.
Delta Lake Optimize
Delta Compaction
Delta Lake optimize provides a robust solution for managing fragmented data files in modern data lakes. The OPTIMIZE command in delta lake optimize addresses the challenge of small files by compacting them into fewer, larger files. This process uses a bin packing algorithm, which groups small files within each partition until the combined size approaches a configurable maximum, typically 1GB. Delta lake optimize executes this operation per partition, preserving data locality and maximizing efficiency.
Delta ensures atomicity and consistency during table compaction by updating the metadata transaction logs. The system leverages ACID transaction support, which guarantees that compaction does not disrupt concurrent reads or writes. The transaction log records every change, maintaining a reliable history and enabling safe recovery if failures occur.
Delta lake optimize not only merges files but also cleans up unnecessary metadata entries and updates statistics. These improvements help the query optimizer select better execution plans, reducing file scan overhead and enhancing query speed.
The following table summarizes the technical steps involved in delta lake optimize table compaction:
| Step | Description |
| File Grouping | Bin packing algorithm groups small files per partition |
| File Writing | System writes out larger files, typically around 1GB |
| Metadata Update | Transaction log records changes atomically |
| Statistics Refresh | Optimizer updates statistics for improved query planning |
| Metadata Cleanup | System removes obsolete metadata entries |
Delta lake optimize stands out from traditional data lakes, where compaction often requires manual intervention and lacks ACID guarantees. In delta, users can trigger table compaction manually using the DeltaTable API or Spark SQL, ensuring predictable and safe file consolidation.
Performance benchmarks reveal that delta lake optimize delivers competitive results compared to other solutions. Delta and Apache Hudi show similar efficiency in write and compaction operations, while Apache Iceberg generally lags behind. Real-world tests, such as those conducted at Walmart, demonstrate that delta lake optimize maintains resilience and longevity under demanding workloads, although some background compaction failures may occur.
Automation
Delta lake optimize supports automation features that streamline table compaction and improve operational efficiency. Optimized Write and Auto Compaction reduce the creation of small files during data ingestion. These features shuffle and combine data before writing, minimizing fragmentation and enhancing query performance.
Delta lake optimize automation proves especially valuable for streaming ingestion workflows. Delta regularly merges small files generated by micro-batch streaming writes into larger, optimized files. This consolidation lowers administrative overhead, improves I/O efficiency, and accelerates queries. Streaming pipelines benefit from reduced latency and faster data access, which enhances overall responsiveness and resource utilization.
Automated table compaction in delta lake optimize organizes data into efficient storage formats, addressing fragmentation and lowering operational costs.
However, automation in delta lake optimize has limitations, particularly for large-scale tables. Auto compaction runs synchronously only on the cluster that performed the write operation. It compacts only files that have not been previously merged, so some small files may persist. Automation triggers only when a minimum number of small files exist, which can delay compaction. Running auto compaction concurrently with DELETE, MERGE, UPDATE, or OPTIMIZE operations may cause transaction conflicts and job failures. For tables exceeding 1 TB, manual OPTIMIZE commands remain necessary to achieve full consolidation and enable advanced features like ZORDER.
Best practices for scheduling table compaction jobs in cloud-based delta environments include:
Use a scheduler-executor architecture, with dedicated thread pools for compaction tasks.
Prioritize partitions with higher compaction scores to optimize resource usage.
Control the maximum number of concurrent compaction tasks to balance workload and performance.
Group compaction tasks by compute node to improve execution efficiency.
Tune scheduler and executor parameters to optimize parallelism and resource consumption.
Monitor compaction scores and resource usage, setting alerts for urgency and memory consumption.
Increase parallel compaction threads during idle periods to accelerate consolidation.
Use management commands to view and cancel compaction tasks as needed.
Delta lake optimize empowers organizations to maintain efficient, scalable data lakes. By combining manual and automated table compaction strategies, delta ensures high performance, reliability, and cost-effectiveness for both batch and streaming workloads.
Benefits and Challenges
Advantages
Organizations gain several measurable benefits by implementing delta compaction in enterprise data lakes. Delta compaction improves query performance, often delivering speed increases of 30-50%. When combined with advanced optimizations such as Z-ordering and data skipping, filtered queries can run up to 100 times faster, and scan times may decrease by 40-60%. These improvements result in lower compute resource usage and significant cost savings. For example, a financial firm using delta compaction and dynamic pruning achieved a fivefold speedup in daily reconciliations, halved storage costs, and doubled query speeds on petabyte-scale data.
Compaction also streamlines data management. Delta Lake incorporates compaction as part of its optimized file management, right-sizing files and reducing metadata overhead. This simplification enhances query efficiency and makes data organization more manageable. Lakehouse architectures rely on compaction to reduce the number of small files, optimize storage layout, and improve overall performance. Upsolver’s Adaptive Optimizer for Apache Iceberg demonstrates storage savings of 23% to 69% compared to traditional approaches, with dramatic reductions in partition and file counts. These strategies directly translate into reduced compute costs and faster query execution.
Delta compaction supports cost optimization strategies, including lifecycle policies and data deduplication, which lower monthly expenses for storage, compute, and data transfer. A 10TB data lake can cost nearly $980 per month, but compaction and file layout optimizations help reduce these costs.
Considerations
Despite its advantages, delta compaction presents several challenges for organizations. Data lakes often use append-only object storage, such as Amazon S3 or Azure Blob Storage, which stores data as log files partitioned by time without indexes. This design makes pinpointing specific records for updates or deletes difficult, requiring full data scans that consume significant resources and time. Organizations may experience delayed responses to change requests and inconsistent data views.
Compaction jobs consume resources by reading and rewriting data files and updating metadata atomically. These jobs must coordinate with ongoing streaming writes, making operational management complex. More resource-intensive strategies, like sort-based compaction, can yield better performance but require careful scheduling to avoid conflicts. Running compaction continuously is critical for maintaining fast query performance, yet it remains operationally challenging.
Compliance requirements, such as GDPR and CCPA, demand record deletion from data lakes. Change Data Capture for real-time replication, fraud detection, and user-based aggregations all require updates to stored data. Ensuring consistency and reliability means organizations must manage mappings between keys and files and merge records efficiently.
Compaction is often run as a background or scheduled job. Teams must balance resource usage, performance gains, and operational complexity to achieve optimal results.
Real-World Impact
Examples
Organizations have observed significant improvements in performance and cost efficiency after implementing delta compaction strategies. A global retailer adopted delta table optimization to manage millions of daily sales events. The team reduced query times by 40% and lowered storage costs by consolidating fragmented files. In another case, a financial institution used delta compaction to streamline daily reconciliation processes. The engineers reported a fivefold increase in query speed and a 50% reduction in compute resource consumption.
Delta compaction also supports compliance-driven data deletion. When a healthcare provider needed to meet strict data retention policies, regular full compactions ensured that deleted records were physically removed from storage. This approach helped the organization maintain regulatory compliance and avoid unnecessary storage expenses.
Scenarios
Shared-data architectures such as Cassandra and YugabyteDB require regular compaction to maintain optimal performance. The following scenarios illustrate the necessity of scheduled compaction:
Workloads with frequent updates and deletions accumulate obsolete data and tombstones. Regular full compactions consolidate data versions and remove outdated tuples, improving read efficiency.
Tables with default TTL benefit from compaction, which efficiently removes expired data and reclaims disk space.
Compliance-driven data deletion mandates full compactions to ensure that tombstoned data is physically removed by a specific date.
Large SST files not compacted by background processes can persist, causing increased disk usage. Scheduled compactions address this issue and maintain database health.
In data lakehouse environments, delta compaction plays a critical role in scaling performance. The table below summarizes how delta compaction supports lakehouse architectures:
| Aspect | Explanation |
| Optimized Query Performance | Merging smaller files reduces the number of files scanned during queries, speeding up execution. |
| Reduced Metadata Overhead | Fewer files lead to less metadata, improving storage management and resource use. |
| Enhanced Data Retrieval | Larger consolidated files enable more efficient I/O operations, reducing data read times. |
| Reduced Storage Costs | Compaction lowers redundancy, cutting storage expenses especially in cloud environments. |
| Storage Growth Control | Helps manage storage expansion in architectures with decoupled compute and storage. |
| Best Practices | Schedule compaction regularly, monitor fragmentation, balance file sizes, test before scaling, and backup data. |
| Common Pitfalls to Avoid | Avoid overcompacting, neglecting monitoring, insufficient testing, and lack of backups. |
Delta compaction mitigates uncontrolled storage growth and supports efficient data retrieval. Teams that schedule compaction jobs and monitor fragmentation maintain high performance and cost-effective operations. A build-by-use-case approach allows organizations to prove value before scaling governance and architecture.
Data professionals gain a competitive edge by mastering delta optimization. Key takeaways include:
Delta rewrites small files into larger, optimized ones, accelerating query performance.
Delta compaction helps systems compete with traditional warehouses for analytics.
Delta combines asynchronous file merging with metadata-layer improvements for efficiency.
To evaluate the need for delta strategies, organizations should:
Monitor query speed and file counts for signs of the small file problem.
Choose between manual, scheduled, or automatic delta compaction based on workload and table format.
Continuously review performance and compliance needs.
Teams that implement delta compaction maintain scalable, cost-effective analytics environments.
FAQ
What triggers the need for data lake compaction?
Frequent ingestion of small files, slow queries, or rising storage costs often signal the need for compaction. Teams should monitor file counts and query performance to decide when to compact.
How often should organizations run compaction jobs?
Most organizations schedule compaction daily or weekly. The ideal frequency depends on data volume, ingestion rate, and query patterns. Regular monitoring helps determine the best schedule.
Does compaction affect data availability?
Compaction in modern systems like Delta Lake runs without blocking reads or writes. Users continue to access data during compaction, ensuring high availability.
Can compaction help with compliance requirements?
Yes. Compaction physically removes deleted records, which supports compliance with regulations like GDPR. This process ensures that sensitive data does not remain in storage after deletion.
What are the risks of overcompacting a data lake?
Overcompaction can waste resources and increase costs. It may also cause unnecessary data rewriting, which can impact performance. Teams should balance compaction frequency with operational needs.