

Stream enrichment in data engineering adds valuable context to real-time information streams, transforming raw data into meaningful insights. Organizations benefit from enhanced data quality and reliability, which leads to more accurate analysis and confident decisions. Enriched information enables teams to identify high-value opportunities and personalize user experiences. Real-time processing and automation allow decision-makers to respond swiftly, supported by up-to-date and trustworthy information.
Key Takeaways
Stream enrichment adds useful context to real-time data, turning raw information into valuable insights for faster, smarter decisions.
Unlike batch processing, stream enrichment works continuously with low delay, making it ideal for time-sensitive tasks like fraud detection and personalization.
The enrichment workflow includes data ingestion, real-time joins, data augmentation, storage, delivery, and ongoing testing to ensure quality and speed.
Different types of enrichment—geographic, demographic, temporal, and behavioral—help businesses understand where, who, when, and how users interact.
Stream enrichment supports key use cases such as fraud detection, personalized experiences, real-time monitoring, and efficient IoT data management.
Scalable, automated, and well-monitored pipelines maintain high data quality and system reliability even as data volumes grow.
Choosing the right tools and platforms depends on factors like scalability, latency, throughput, integration ease, and cost.
Security and privacy are essential; organizations must follow regulations, use encryption, obtain user consent, and perform regular audits to protect data.
Stream Enrichment Overview
What is Stream Enrichment
Stream enrichment refers to the process of enhancing raw data as it flows through data streams by adding relevant context or supplementary information. This process transforms basic event records into richer, more valuable datasets. Data enrichment can involve joining incoming data with reference datasets, appending metadata, or correlating events with historical records. Streaming enrichment enables organizations to make sense of real-time information, supporting immediate analysis and action. By enriching data in motion, teams can unlock deeper insights and improve the quality of downstream analytics.
Stream Enrichment vs. Batch Processing
Traditional batch processing and stream enrichment differ in how they handle data latency and throughput. Batch processing collects large volumes of data and processes them at scheduled intervals. This approach optimizes throughput by handling data in bulk, but it introduces higher latency because data must wait for the next batch window. Batch processing works well for stable datasets and historical analysis, offering comprehensive validation and cost efficiency.
In contrast, streaming enrichment processes data continuously as it arrives. This method provides very low latency, making enriched data available almost instantly. Stream processing supports real-time analytics, but maintaining high throughput can be challenging due to the need for constant resource allocation and the complexity of scaling. Organizations use streaming enrichment for time-sensitive applications where immediate insights and actions are critical, such as fraud detection or patient monitoring.
“AI-driven decision-making needs millisecond-level freshness, not insights delayed by hours or days. If your AI isn’t reacting in real time, it’s already obsolete.” — Striim expert insight
Why Stream Enrichment Matters
Streaming enrichment delivers significant advantages for organizations seeking to maximize the value of their data. The ability to enrich data streams in real time leads to several measurable business outcomes:
Reduction in decision-making time from hours or days to minutes
Improved customer satisfaction, as seen in companies like Zendesk
Increased operational efficiency and competitive advantage
Adoption of advanced tools, such as Striim, enabling millisecond-level data freshness
Many organizations report substantial improvements after implementing data enrichment strategies. For example, studies show that companies using data enrichment experience a 10-15% increase in revenue and a 5-10% reduction in costs. Over 80% of organizations consider data enrichment essential for business success. Netflix leverages real-time enrichment to personalize recommendations, which boosts user engagement and satisfaction.
| Business Outcome | Measurable Result |
| Revenue Growth | 25% increase |
| Profitability | 30% higher |
| Data Accuracy | Over 40% reduction in errors |
| Customer Satisfaction | 70% improvement |
| Customer Insights | 60% enhancement |
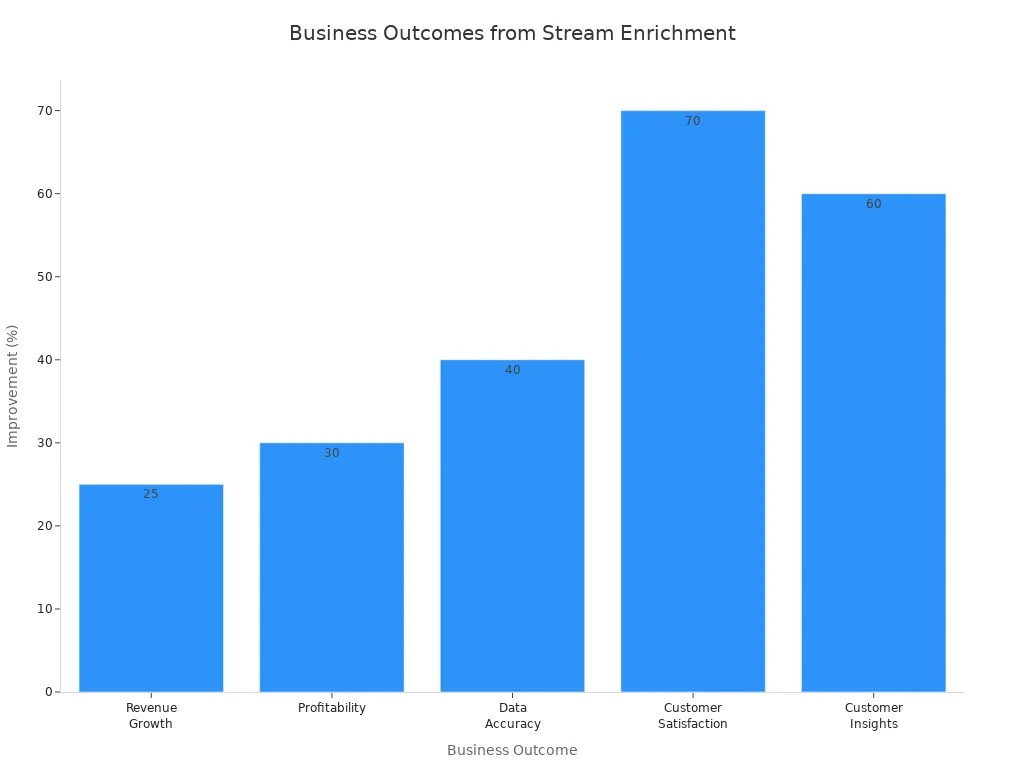
Organizations that invest in streaming enrichment gain the ability to respond quickly to changing market conditions and customer behaviors. Real-time data enrichment supports enhanced decision-making, operational efficiency, and customer satisfaction, making it a cornerstone of modern data engineering.
How Stream Enrichment Works
Core Workflow
Stream enrichment transforms raw data into actionable insights by following a structured workflow. Each stage plays a critical role in ensuring that enriched information is accurate, timely, and ready for downstream analytics.
Data Ingestion
Data ingestion marks the entry point for data enrichment. Systems collect data in real time from sources such as webhooks, event streams, and APIs. The ingestion layer acts as a buffer, ensuring reliability and scalability even during spikes in data volume. Data producers may generate thousands of events per second, so the architecture must accommodate varying frequencies and volumes. Technologies like Apache Kafka often serve as the backbone for scalable data ingestion, enabling seamless handling of high-throughput data streams.
Real-Time Joins and Lookups
After ingestion, the workflow moves to real-time joins and lookups. At this stage, enrichment logic applies data cleaning, normalization, and augmentation techniques. The system joins incoming records with reference datasets or external sources to add context. For example, a transaction event may be joined with customer profile data to append demographic details. Real-time processing ensures that these joins happen with minimal delay, supporting immediate analytics and decision-making. Distributed frameworks like Apache Flink enable parallel processing, which increases throughput and reduces latency.
Data Augmentation
Data augmentation further enhances the value of each record. The system appends metadata, correlates events with historical records, or enriches information with external attributes. After augmentation, the workflow delivers enriched data to downstream systems using webhooks, streaming APIs, or message queues. Storage solutions such as cloud-based data warehouses or NoSQL databases store both real-time and historical data, scaling as needed. Continuous testing and monitoring ensure data quality and system performance throughout the workflow.
Tip: Regularly monitor and test each stage of the workflow to maintain high data quality and system reliability.
Data Ingestion: Collect real-time data from diverse sources.
Enrichment Processing: Clean, normalize, and augment raw data.
Storage: Select storage solutions based on data volume and use case.
Delivery Mechanisms: Make enriched data available to downstream systems.
Testing and Monitoring: Ensure data quality and system performance.
Handling External Data Sources
Integrating external data sources into streaming enrichment pipelines introduces complexity. Systems must merge information from various formats, databases, and platforms into a unified view. Challenges often arise from inconsistent data models, poor data quality, and the sheer volume and velocity of incoming information. Data profiling and quality management become essential to identify and resolve inconsistencies before enrichment. Enterprises rely on robust integration solutions, including master data management and comprehensive profiling, to address these challenges.
| Challenge | Description |
| Inconsistent Data Formats and Models | Differences in formats and classification schemes require mapping and master data management. |
| Poor Data Quality | Human error, outdated information, and previous integration errors necessitate quality management strategies. |
| Volume, Velocity, and Variety | Large, fast, and diverse data streams demand scalable and flexible integration strategies. |
| Need for Robust Integration | Enterprise-grade tools and processes are essential for effective integration and enrichment. |
Selecting the right integration strategy depends on data velocity and complexity. Real-time integration suits high-speed data, while batch processing may fit less time-sensitive information. Preparation and assessment remain crucial for successful data enrichment.
Performance and Latency
Performance and latency define the effectiveness of stream enrichment systems. High data volumes require scalable architectures that maintain sub-second latency. Distributed processing frameworks, such as Apache Flink, leverage features like disaggregated state management and materialized tables to optimize resource use. These choices result in increased operational efficiency and reduced costs.
To minimize latency in real-time processing, organizations employ several techniques:
Partition data for parallel processing, increasing throughput.
Add nodes to distribute load and improve scalability.
Optimize network protocols and use in-memory computations to reduce delays.
Dynamically adjust resources, such as CPU and memory, to match data loads.
Maintain state information for complex event processing.
Set up alerts for unusual behavior or performance degradation.
Optimize data flows to reduce redundant processing.
Ensure continuous operation with real-time monitoring and alerting.
As data volume grows, each component of the workflow—from ingestion to storage—must scale accordingly. Real-world pipelines have demonstrated the ability to handle over 10,000 events per second with sub-second latency, resulting in significant gains in efficiency and cost reduction. Careful architectural choices and modern stream processing capabilities are critical for maintaining performance as demands increase.
Types of Data Enrichment
Geographic Enrichment
Geographic enrichment adds spatial context to raw data, transforming simple coordinates or addresses into actionable insights. Businesses use this form of data enrichment to append postal codes, city names, geographic boundaries, and even real-time weather patterns to their data streams. Modern location intelligence platforms, such as Esri ArcGIS and Google Cloud Location-Based Services, deliver accurate and up-to-date geographic data. These tools help organizations optimize operations, improve marketing strategies, and gain a competitive edge.
Geographic enrichment enables companies to understand where their customers are, how they move, and what local factors influence their behavior.
Techniques like reverse geocoding convert latitude and longitude into readable addresses, while proximity analysis reveals spatial relationships between customers and business locations. Spatial joins combine location data with other datasets, uncovering patterns that drive decisions in retail, healthcare, and logistics. For example, a food delivery app can recommend nearby restaurants by enriching order data with geolocation. Uber used geospatial enrichment to reduce wait times by 30% and increase customer satisfaction by 25%. The growing importance of this approach is clear, with the location intelligence market expected to nearly double from $12.3 billion in 2020 to $23.6 billion by 2025.
Location Data
Location data forms the foundation of geographic enrichment. By adding GPS coordinates, ZIP codes, and regional trends, organizations can:
Personalize marketing campaigns based on user location.
Optimize supply chains and reduce transportation costs.
Segment customers by geographic behavior.
Analyze competitors using location-based strategies.
Real-time geographic enrichment empowers businesses to make faster, more informed decisions, enhancing both customer experience and operational efficiency.
Demographic Enrichment
Demographic enrichment enhances data streams by appending personal attributes such as age, gender, income, education, and job title. This type of data enrichment is essential for effective customer segmentation. Companies group users by shared characteristics, which helps them understand communities and target decision-makers more precisely.
Demographic enrichment supports highly customized campaigns and product development by revealing the needs and preferences of different user groups.
Marketers use enriched demographic data to refine targeting and messaging. For instance, knowing the proportion of women in affluent regions allows brands to tailor marketing efforts and establish a strong presence. Combining demographic and behavioral data enables businesses to predict purchasing trends and optimize store locations. Personalization driven by demographic enrichment can reduce acquisition costs by up to 50%, increase revenue by 5-15%, and boost marketing efficiency by 10-30%.
User Profiles
User profiles aggregate demographic attributes, providing a comprehensive view of each customer. With enriched user profiles, organizations can:
Deliver targeted content and offers.
Increase engagement and retention rates.
Optimize marketing spend by focusing on relevant segments.
Build accurate buyer personas for future campaigns.
This approach leads to clearer, actionable insights and more effective outreach.
Temporal Enrichment
Temporal enrichment adds time-related context to event-driven data streams. By incorporating timestamps, event history, and session data, organizations gain a deeper understanding of when and how events occur. Stateful stream processing plays a key role, maintaining memory of past events and enabling systems to correlate current events with historical data.
Temporal enrichment allows businesses to detect trends, analyze seasonality, and correlate events over time for more informed decision-making.
This type of data enrichment improves the relevance and richness of event data. It supports real-time decision-making and complex event processing, which are critical in industries like finance, e-commerce, and IoT.
Timestamps and Event Context
Timestamps and event context provide the temporal dimension needed for advanced analytics. By enriching data streams with this information, organizations can:
Track user journeys across sessions.
Identify peak activity periods.
Detect anomalies and trigger alerts in real time.
Analyze the impact of external events on business performance.
Temporal enrichment ensures that every event carries the context required for accurate, timely insights.
Behavioral Enrichment
Behavioral enrichment focuses on enhancing data streams by adding information about user actions, preferences, and engagement patterns. This approach allows organizations to understand not just who their users are or where they are located, but also how they interact with products, services, or platforms. By capturing and enriching behavioral data in real time, companies can gain a deeper understanding of customer journeys and optimize their offerings accordingly.
Behavioral data enrichment often involves tracking events such as clicks, page views, purchases, and navigation paths. These actions reveal user intent and help organizations predict future behavior. For example, an e-commerce platform can enrich its data streams by recording which products a user views, adds to a cart, or purchases. This enriched data supports advanced analytics, such as recommendation engines and churn prediction models.
Behavioral enrichment transforms raw activity logs into actionable insights, enabling businesses to deliver personalized experiences and targeted interventions.
User Actions
User actions form the core of behavioral enrichment. Every interaction a user has with a digital system generates valuable signals. By applying data enrichment techniques, organizations can link these signals to broader user profiles, session histories, and contextual information. This process creates a comprehensive view of each user's behavior over time.
Key types of user actions commonly used in behavioral enrichment include:
Clickstream Events: Track every click, scroll, or navigation event on a website or app.
Transaction Records: Capture purchases, returns, and payment activities.
Engagement Metrics: Measure time spent on pages, frequency of visits, and content interactions.
Feature Usage: Monitor which features or tools users access most frequently.
A table below summarizes how behavioral data enrichment enhances business outcomes:
| User Action Type | Enrichment Example | Business Benefit |
| Clickstream | Session context, device info | Improved UX, targeted offers |
| Transactions | Product metadata, loyalty status | Upselling, fraud detection |
| Engagement | Demographic overlay, time stamps | Retention, content optimization |
| Feature Usage | Role-based access, usage trends | Product development, support |
Data enrichment in this context enables real-time personalization. For instance, a streaming service can recommend shows based on recent viewing habits, while a banking app can flag unusual transactions for fraud prevention. Behavioral enrichment also supports A/B testing, campaign measurement, and customer segmentation.
Tip: To maximize the value of behavioral enrichment, organizations should ensure data privacy and comply with relevant regulations. Anonymizing user actions and securing enriched datasets protect both users and the business.
By integrating behavioral data enrichment into their pipelines, companies can respond quickly to changing user needs and market trends. This approach drives engagement, loyalty, and long-term growth.
Stream Enrichment Use Cases
Fraud Detection
Financial institutions rely on stream enrichment to strengthen fraud detection systems. By aggregating additional data points from diverse sources, such as IoT sensors, ATMs, and social media, organizations build comprehensive user profiles. Machine learning models analyze these enriched profiles to identify suspicious behavior and potential risks. Payment enrichment adds attributes like geolocation and fraud scores to transactions, allowing banks to spot unusual patterns quickly. For example, repeated ATM withdrawals in different locations may trigger immediate alerts.
Stream enrichment enables real-time transformations, filtering, and correlation of incoming data streams. Oracle GoldenGate Stream Analytics performs in-memory computations, supporting instant fraud prevention actions. Banks can notify customers or block compromised cards within seconds. This approach complements batch ingestion by providing continuous insights, improving the efficiency and accuracy of fraud detection.
Stream enrichment empowers financial services to act on threats as they emerge, protecting both customers and institutions.
Key steps in fraud detection using stream enrichment:
Ingest real-time data from multiple sources.
Transform and correlate data to detect suspicious patterns.
Trigger immediate actions, such as alerts or card blocks.
Continuously update fraud detection models with enriched data.
Personalization
Stream enrichment drives advanced personalization in digital platforms. By integrating diverse data sources, organizations deliver hyper-personalized content and product recommendations. AI-powered engines update dynamic lead personas in real time, improving relevance and accuracy. Behavioral triggers and adaptive customer journeys ensure users receive timely, tailored experiences.
Marketers observe significant improvements in segmentation, engagement, and loyalty. For instance, Netflix uses enriched data streams to power its recommendation engine, resulting in a 75% increase in user engagement. Amazon’s personalized product suggestions boost conversion rates by 25%. Companies also report shorter sales cycles and higher customer lifetime value.
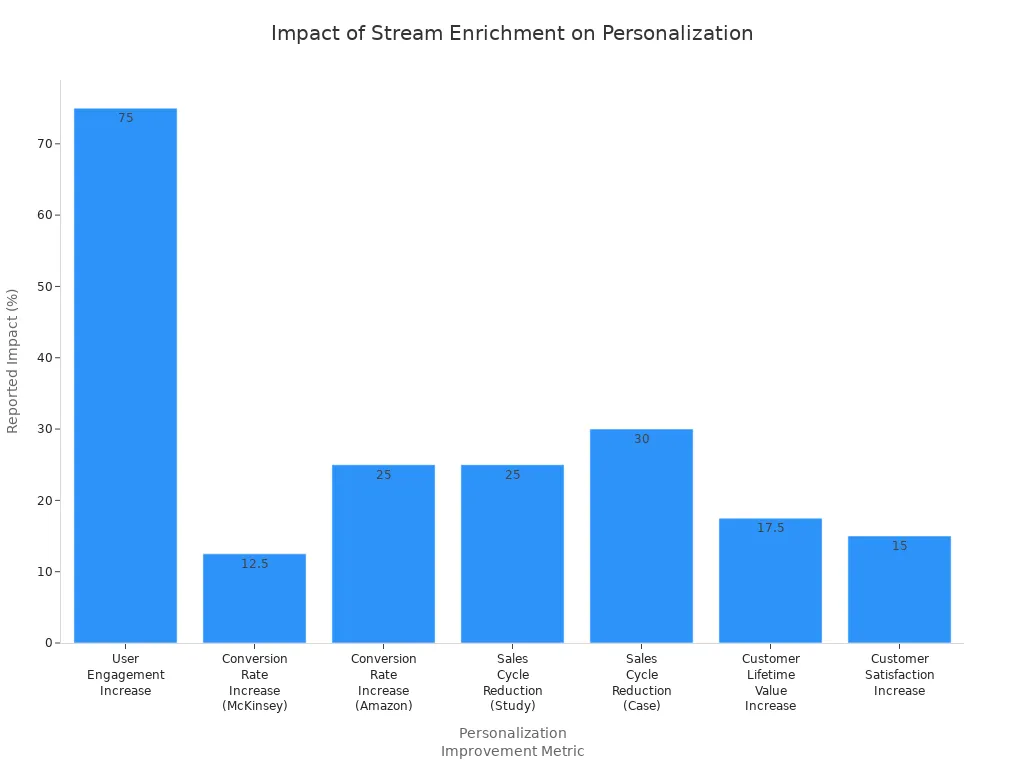
| Benefit Area | Evidence / Data Spark | Reported Impact |
| Improved Segmentation & Targeting | Marketers using advanced segmentation | 760% increase in revenue |
| Enhanced Engagement Rates | Personalized marketing campaigns | Up to 20% increase |
| Increased Customer Loyalty | Customer expectations for personalization | 63% expect personalization as standard |
Personalization powered by stream enrichment leads to higher engagement, conversion rates, and customer satisfaction.
Monitoring and Alerts
Operational systems depend on stream enrichment for real-time monitoring and alerting. Platforms like Microsoft Fabric ingest raw sensor and weather data streams, enrich them through transformations, and join with reference data. This process enables organizations to define alert conditions directly on streaming data and trigger notifications or workflows instantly. Contoso, for example, correlates indoor sensor readings with outdoor weather to improve anomaly detection and operational decisions.
Enriched streams feed live dashboards, providing operational visibility and supporting event-driven automation. Tiger Lake architecture unifies live event streams with historical data, reducing latency and complexity. Organizations respond faster to changing conditions, benefiting industries such as manufacturing, retail, logistics, and finance.
Stream enrichment filters, standardizes, and masks sensitive information to maintain data quality.
Real-time monitoring enables immediate detection of trends and anomalies.
Event-driven platforms scale easily, updating dashboards and triggering alerts as data flows in.
Real-time monitoring and alerting powered by stream enrichment support faster, clearer responses to operational challenges.
IoT Data Streams
Stream enrichment plays a pivotal role in the management and analysis of IoT data streams, especially within industrial environments. IoT devices generate vast amounts of raw data, often in real time, which can overwhelm traditional processing systems. By enriching these streams, organizations transform basic sensor readings into actionable insights that drive operational improvements.
Industrial IoT deployments face unique challenges. Devices often operate with limited computational resources and communicate over heterogeneous protocols. Stream enrichment addresses these issues by merging analytic outcomes with original data streams, enabling local decision-making and reducing latency. Processing data at the network edge allows organizations to respond quickly to events, which is critical for applications such as predictive maintenance and process automation.
Edge-based stream enrichment empowers factories and plants to detect anomalies, anticipate equipment failures, and optimize resource allocation without waiting for centralized analysis.
Key benefits of stream enrichment for IoT data streams in industrial applications include:
Merging analytic results with raw IoT data enables immediate, localized decision-making.
Edge processing reduces network traffic and latency, supporting real-time responsiveness.
Enriched streams provide timely and accurate information for operational efficiency and predictive maintenance.
Analytics performed closer to the data source improve accuracy and facilitate real-time event detection.
Standardized architectures, such as STEAM, simplify IoT application development by unifying data acquisition, enrichment, and communication across diverse devices.
A typical industrial IoT stream enrichment workflow involves several steps:
Data acquisition from sensors and devices.
Local preprocessing and enrichment at the edge.
Transmission of enriched data to centralized systems for further analysis or storage.
Real-time event detection and alerting based on enriched information.
The following table summarizes how stream enrichment enhances industrial IoT operations:
| Benefit | Description |
| Reduced Latency | Decisions made locally, minimizing delays |
| Lower Network Overhead | Less data sent to central servers |
| Improved Data Accuracy | Analytics performed near the source |
| Predictive Maintenance | Early detection of equipment issues |
| Simplified Development | Unified architecture across devices and protocols |
Organizations that implement stream enrichment in their IoT pipelines gain a competitive edge. They achieve faster response times, reduce operational costs, and improve system reliability. As IoT ecosystems continue to expand, stream enrichment will remain essential for harnessing the full potential of real-time data.
Best Practices for Stream Enrichment
Scalability
Scalability stands as a cornerstone for any robust stream enrichment architecture. As data volumes grow, systems must process more events without sacrificing speed or reliability. Teams often use the Scatter-Gather pattern to parallelize independent enrichment tasks, allowing multiple services to handle data at the same time and reduce latency. The Aggregator pattern then collects and combines partial results, ensuring a single, complete enriched output. For tasks that depend on previous results, the Chain of Responsibility pattern provides a flexible, ordered approach.
Distributed, event-driven microservices communicate through messaging systems like Kafka or AWS SQS/SNS. This design decouples components and enables horizontal scaling. Redis, or AWS ElastiCache, serves as a fast-access store for partial results, helping coordinate task completion and reducing direct dependencies between services. Teams ensure a single atomic database write per enriched event to maintain consistency and reduce load. Running multiple instances of enrichment services, each consuming from dedicated queues, allows the system to handle increased demand efficiently. Decoupling producers and consumers through messaging systems helps manage backpressure and improves resilience. Managed cloud services support scalability and reliability while reducing operational overhead. Microservices should remain loosely coupled, each responsible for a specific enrichment, which makes the system easier to maintain and extend.
Automation
Automation optimizes stream enrichment pipelines by orchestrating workflows from extraction through transformation and loading. Tools like Apache Airflow and FiveTran enable continuous, real-time processing and integration from diverse sources. These platforms automate error checking, cleaning, and validation, ensuring consistent data quality. Low-code solutions such as ActiveBatch provide event-driven scheduling, centralized monitoring, and secure integration, streamlining pipeline management.
Automation reduces human errors and accelerates data processing. IT teams can focus on strategic initiatives rather than manual intervention. Automated pipelines also manage complexity from multiple data sources and formats, enforcing consistent standards and compliance. Real-time or near-real-time processing, enabled by automation, delivers timely insights for decision-making.
Continuous monitoring of pipeline performance, errors, and data quality keeps operations smooth.
Automated data cleaning removes duplicates, corrects errors, and handles missing values.
Automation enhances datasets with additional information, supporting high data quality.
Efficient pipelines lower costs and boost productivity.
Tip: Automation not only improves operational efficiency but also ensures that data quality remains high as systems scale.
Data Quality
Maintaining high data quality is essential for effective stream enrichment. Teams handle missing or erroneous data using methods such as data imputation, validation, and cleansing. Data imputation replaces missing values with estimates, while validation checks data against defined rules. Cleansing corrects or removes errors to ensure accuracy.
Handle missing or erroneous data with imputation, validation, and cleansing.
Validate enriched data through profiling, quality metrics, and reconciliation with original data.
Continuously monitor data quality by tracking metrics and performing regular validation and cleansing.
Teams also ensure that third-party data aligns with business goals to avoid unnecessary processing. Consistency remains critical; teams verify uniform quality and structure, standardize formats, and plan for ongoing quality monitoring. Accessibility matters as well, so data can be integrated quickly and cost-effectively.
A focus on data quality at every stage of the enrichment process leads to more reliable analytics and better business outcomes.
Monitoring
Effective monitoring forms the backbone of any successful stream enrichment pipeline. Teams must track system health, performance, and data flow in real time to ensure reliability. Monitoring helps detect bottlenecks, failures, and anomalies before they impact downstream analytics or business operations.
Modern data engineering teams use a combination of metrics, logs, and alerts to maintain visibility. Metrics provide quantitative insights into throughput, latency, error rates, and resource utilization. Logs capture detailed event histories, which help diagnose issues and trace data lineage. Alerts notify engineers when thresholds are breached or unexpected patterns emerge.
A robust monitoring strategy includes several key components:
Real-Time Dashboards: Visualize system status, data flow, and enrichment outcomes. Dashboards help teams spot trends and react quickly to incidents.
Automated Alerts: Trigger notifications for latency spikes, dropped events, or failed enrichments. Automated alerts reduce response times and prevent data loss.
Health Checks: Regularly verify the availability and responsiveness of enrichment services and dependencies.
End-to-End Tracing: Track data as it moves through each stage of the pipeline. Tracing supports root cause analysis and compliance audits.
Tip: Set clear thresholds for critical metrics. Review and update alerting rules as the system evolves.
The following table summarizes common monitoring metrics and their significance:
| Metric | Description | Why It Matters |
| Throughput | Number of events processed per second | Measures system capacity |
| Latency | Time from ingestion to enrichment | Indicates real-time performance |
| Error Rate | Percentage of failed enrichment attempts | Highlights data or system issues |
| Resource Utilization | CPU, memory, and storage usage | Guides scaling and optimization |
Continuous monitoring supports proactive maintenance. Teams can identify trends, forecast capacity needs, and plan upgrades before problems arise. Monitoring also plays a vital role in maintaining data quality. By tracking error rates and enrichment failures, teams can address issues early and prevent corrupted or incomplete data from reaching downstream consumers.
In regulated industries, monitoring provides audit trails and supports compliance. Detailed logs and traces demonstrate that data handling meets legal and organizational standards.
To maximize the value of monitoring, organizations should:
Integrate monitoring tools with incident management platforms.
Automate reporting and escalation workflows.
Regularly review monitoring configurations and update them as requirements change.
Monitoring transforms stream enrichment from a reactive process into a proactive, resilient system. Teams gain confidence in their pipelines and deliver consistent, high-quality insights to the business.
Tools and Platforms
Selecting the right tools and platforms is crucial for building effective stream enrichment pipelines. Both open source frameworks and cloud services offer robust solutions for real-time processing, transformation, and enrichment.
Open Source Tools
Open source tools provide flexibility and control for organizations that want to customize their stream enrichment workflows. The following table summarizes widely used options and their strengths:
| Tool | Role/Use Case | Key Features & Strengths |
| Apache Kafka | Distributed stream-processing | High throughput, low latency, fault-tolerant, exactly-once delivery, scalable partitions, multi-language support |
| Apache NiFi | Data integration & enrichment | Real-time data routing, transformation, enrichment, visual flow management, supports batch & real-time processing |
| Apache Flink | Stream processing | Low-latency processing, windowing, aggregations, time-based analysis |
| Talend | ETL and data enrichment | End-to-end ETL, wide connectivity, data profiling, cleansing, supports real-time and batch processing |
| Airbyte | Data ingestion & ELT | 600+ connectors, supports batch and incremental sync, open-source with cloud options |
Apache Flink
Apache Flink specializes in low-latency stream processing. It supports advanced windowing, aggregations, and time-based analysis. Flink’s stateful processing and fault tolerance make it suitable for mission-critical applications. Many organizations choose Flink for scenarios that demand real-time analytics and rapid response.
Apache Kafka Streams
Kafka Streams extends Apache Kafka’s capabilities by enabling in-stream processing and enrichment. It offers high throughput and exactly-once semantics. Kafka Streams integrates seamlessly with existing Kafka deployments, making it a popular choice for scalable, distributed stream enrichment.
Cloud Services
Cloud platforms simplify deployment and scaling for stream enrichment. They offer managed services that reduce operational overhead and integrate with broader cloud ecosystems.
AWS Kinesis
AWS Kinesis delivers a fully managed, serverless streaming service. It includes components such as Kinesis Data Streams, Firehose, and Data Analytics, which supports Apache Flink. Kinesis automatically scales to match throughput requirements and integrates natively with AWS services like Lambda, S3, Redshift, and DynamoDB. Organizations benefit from millisecond-level latency and seamless enrichment across the AWS ecosystem.
Google Dataflow
Google Dataflow provides a fully managed, cloud-based stream processing service built on Apache Beam. It supports both batch and real-time processing, automatic scaling, and dynamic resource management. Dataflow integrates with Google Cloud services such as BigQuery and Pub/Sub. Its windowing and event-time processing features enable efficient enrichment for analytics and machine learning pipelines.
Note: Both AWS Kinesis and Google Dataflow emphasize scalability, low latency, and deep integration with their respective cloud platforms, making them ideal for large-scale, real-time enrichment.
Tool Selection
Choosing the right stream enrichment tool depends on several criteria. The table below outlines key considerations:
| Criteria | Description | Real-World Example / Notes |
| Scalability | Ability to handle increasing data volumes and user demand. | Netflix uses Apache Kafka to process over 500 billion events per day. |
| Latency | Speed of data processing and response time. | Apache Flink offers low latency (5-10 ms), critical for real-time analytics. |
| Throughput | Volume of data processed per unit time. | Goldman Sachs uses Kafka for high throughput financial data processing. |
| Ease of Integration | Compatibility with existing infrastructure and data sources. | Snowflake supports integration with Salesforce, Amazon S3, etc. |
| Fault Tolerance | System reliability and ability to handle failures without data loss. | Apache Flink provides advanced stateful processing for fault tolerance. |
| Cost Considerations | Total cost of ownership including infrastructure, licensing, and maintenance. | Kafka’s TCO can range from $100,000 to $500,000+ per year depending on scale. |
Tip: Teams should evaluate their use case requirements, existing infrastructure, and long-term scalability needs before selecting a stream enrichment platform.
Challenges and Considerations
Latency Issues
Stream enrichment pipelines often face latency challenges that can disrupt real-time analytics. High join amplification stands out as a frequent problem. When a single input record matches many records in another stream or table, the system produces a burst of output data. This surge causes backpressure, where slow downstream operators signal upstream operators to reduce speed. The result is increased latency throughout the pipeline. Backpressure also delays checkpoint barriers, which raises barrier latency and slows the entire stream processing system.
Modern platforms such as RisingWave address these issues by introducing unaligned joins. This technique buffers the join output, isolating the join operator from downstream operators. Buffering allows checkpoint barriers to bypass the buffered data, preventing the pipeline from slowing down. Although buffering introduces a slight increase in localized end-to-end latency, it stabilizes the pipeline and maintains low barrier latency. Engineers can enable unaligned joins with a simple configuration, ensuring checkpoint barriers flow through unimpeded. This approach keeps the pipeline responsive, even when downstream operators lag.
Tip: Buffering join outputs and enabling unaligned joins help maintain low latency and stable performance in high-throughput environments.
Common latency challenges in stream enrichment:
High join amplification causing output bursts
Backpressure propagating latency
Delayed checkpoint barriers increasing barrier latency
Buffering techniques stabilizing pipeline performance
Data Volume
Growing data volumes present significant challenges for stream enrichment systems. As organizations ingest more data from diverse sources, maintaining data quality becomes critical. Continuous cleansing, validation, and enrichment ensure that insights remain reliable. Scalable architectures must adapt dynamically to varying loads, supporting both speed and accuracy.
Teams use horizontal scaling, auto-scaling, and load balancing to distribute workloads efficiently. Data ingestion optimization methods, such as partitioning and compression, improve throughput and reduce latency. Fault tolerance mechanisms, including replication, checkpointing, and exactly-once processing, safeguard data reliability during failures. Real-time processing and event-driven architectures enable timely enrichment and immediate insights.
Monitoring, alerting, and security practices play a vital role as data volume grows. These measures help maintain system health and compliance. Dynamic data enrichment empowers organizations to keep information accurate, complete, and timely, supporting efficient and reliable stream enrichment.
Key strategies for managing data volume:
Implement scalable architectures with dynamic adjustment
Optimize data ingestion using partitioning and compression
Ensure fault tolerance with replication and checkpointing
Use real-time processing for immediate enrichment
Monitor and secure systems to maintain compliance
Reference Data Updates
Reference data forms the backbone of many enrichment processes. Keeping this data current and synchronized with streaming pipelines poses unique challenges. Outdated reference data can lead to inaccurate enrichment, which affects downstream analytics and decision-making. Frequent updates, schema changes, and versioning complicate integration efforts.
Organizations must establish robust update mechanisms for reference datasets. Automated synchronization ensures that enrichment logic always uses the latest information. Version control and schema management help teams track changes and maintain compatibility. Real-time update propagation minimizes the risk of stale data entering the pipeline.
A table below summarizes best practices for managing reference data updates:
| Practice | Benefit |
| Automated synchronization | Ensures up-to-date enrichment |
| Version control | Tracks changes and compatibility |
| Schema management | Maintains integration stability |
| Real-time propagation | Reduces risk of stale data |
Note: Regularly updating and validating reference data protects the integrity of enriched streams and supports accurate, actionable insights.
Security and Privacy
Security and privacy stand as critical pillars in stream enrichment, especially for organizations operating in regulated industries. Data engineers must address legal requirements, ethical considerations, and technical safeguards to protect sensitive information throughout the enrichment process. Regulations such as GDPR and CCPA impose strict rules on how companies collect, process, and store personal data. Failure to comply can result in severe penalties and reputational damage.
Stream enrichment pipelines often handle large volumes of personal and behavioral data. This data can include user profiles, location information, and transaction records. Protecting these datasets from unauthorized access and cyberattacks requires a multi-layered approach. Companies must validate and cleanse incoming data to ensure accuracy before enrichment. Advanced encryption techniques secure data both in transit and at rest. Secure storage solutions, such as encrypted cloud databases, help prevent breaches and data leaks.
Transparency remains essential in building trust with users. Organizations must inform individuals about data collection and enrichment activities. Explicit user consent forms the foundation of ethical data usage. Companies should provide clear options for users to access, modify, or delete their personal information. These measures respect data subject rights and support compliance with privacy laws.
Professional data service providers play a vital role in managing enriched datasets. They specialize in sourcing accurate data, maintaining regular updates, and ensuring compliance with industry standards. Regular security audits and monitoring activities help organizations identify vulnerabilities and maintain accountability.
A robust security and privacy strategy for stream enrichment includes the following best practices:
1. Use first-party data whenever possible to reduce compliance risks and improve data quality. 2. Ensure transparency and obtain explicit user consent for data collection, processing, and enrichment. 3. Partner only with GDPR-compliant data enrichment providers and establish clear data processing agreements. 4. Implement data anonymization and pseudonymization to minimize exposure of personal data. 5. Conduct regular audits of data processing activities to maintain compliance and accountability. 6. Respect data subject rights by providing tools for data access, modification, and deletion.
Tip: Regular audits and transparent communication help organizations maintain compliance and build trust with users.
The table below summarizes key security and privacy considerations for stream enrichment:
| Consideration | Description | Benefit |
| Legal Compliance | Adherence to GDPR, CCPA, and other regulations | Avoids penalties, builds trust |
| Data Accuracy | Validation and cleansing of enriched data | Ensures reliable insights |
| Encryption | Secures data in transit and at rest | Prevents unauthorized access |
| User Consent | Explicit permission for data usage | Supports ethical practices |
| Anonymization | Removes personal identifiers | Minimizes privacy risks |
| Regular Audits | Ongoing review of data handling | Maintains accountability |
Security and privacy must remain at the forefront of every stream enrichment initiative. By following industry best practices and maintaining a proactive approach, organizations can safeguard sensitive information, comply with regulations, and deliver trustworthy insights to stakeholders.
Stream enrichment transforms real-time data pipelines, enabling organizations to gain actionable insights and drive smarter analytics. Selecting the right tools and techniques ensures reliable, scalable enrichment. Teams that follow best practices and monitor new technologies stay ahead in a fast-changing landscape.
Apply proven strategies for data quality and automation.
Explore advanced enrichment methods to future-proof solutions.
Staying informed about emerging trends helps data engineers build robust, adaptable pipelines.
FAQ
What is the main benefit of stream enrichment?
Stream enrichment adds context to raw data in real time. This process helps organizations make faster, more accurate decisions. Teams gain actionable insights without waiting for batch processing.
How does stream enrichment differ from ETL?
ETL processes data in batches and often introduces delays. Stream enrichment works on data as it arrives. This approach supports immediate analytics and real-time responses.
Which industries use stream enrichment most?
Financial services, e-commerce, healthcare, and manufacturing rely heavily on stream enrichment. These sectors need instant insights for fraud detection, personalization, and operational monitoring.
Can stream enrichment handle unstructured data?
Yes. Modern platforms process both structured and unstructured data. They enrich logs, text, images, and sensor data by adding metadata or linking to reference datasets.
What are common challenges in stream enrichment?
Teams face latency, data quality, and integration issues. Managing high data volumes and keeping reference data updated also present challenges.
Is stream enrichment secure?
Stream enrichment can be secure. Teams use encryption, access controls, and regular audits. Compliance with regulations like GDPR ensures data privacy and protection.
How do organizations monitor stream enrichment pipelines?
Organizations use dashboards, automated alerts, and logs. These tools track throughput, latency, and errors. Real-time monitoring helps maintain system health and data quality.