

RisingWave, the open-source distributed SQL database for stream processing, has been gaining traction for its ability to simplify real-time analytics. But as our users started building larger, more demanding applications, we hit a surprising performance bottleneck: etcd, our metadata store. In this post, we'll share why we made the decision to replace etcd with a Postgres-backed meta store, the challenges we faced, and how this seemingly "old-school" approach unlocked a new level of scalability and developer productivity for RisingWave.
The Importance of the Meta Store in RisingWave
Think of the meta store as the "brain" of a RisingWave cluster. It's responsible for storing critical information that keeps the entire system running smoothly.
Here's a simplified view of RisingWave's architecture:
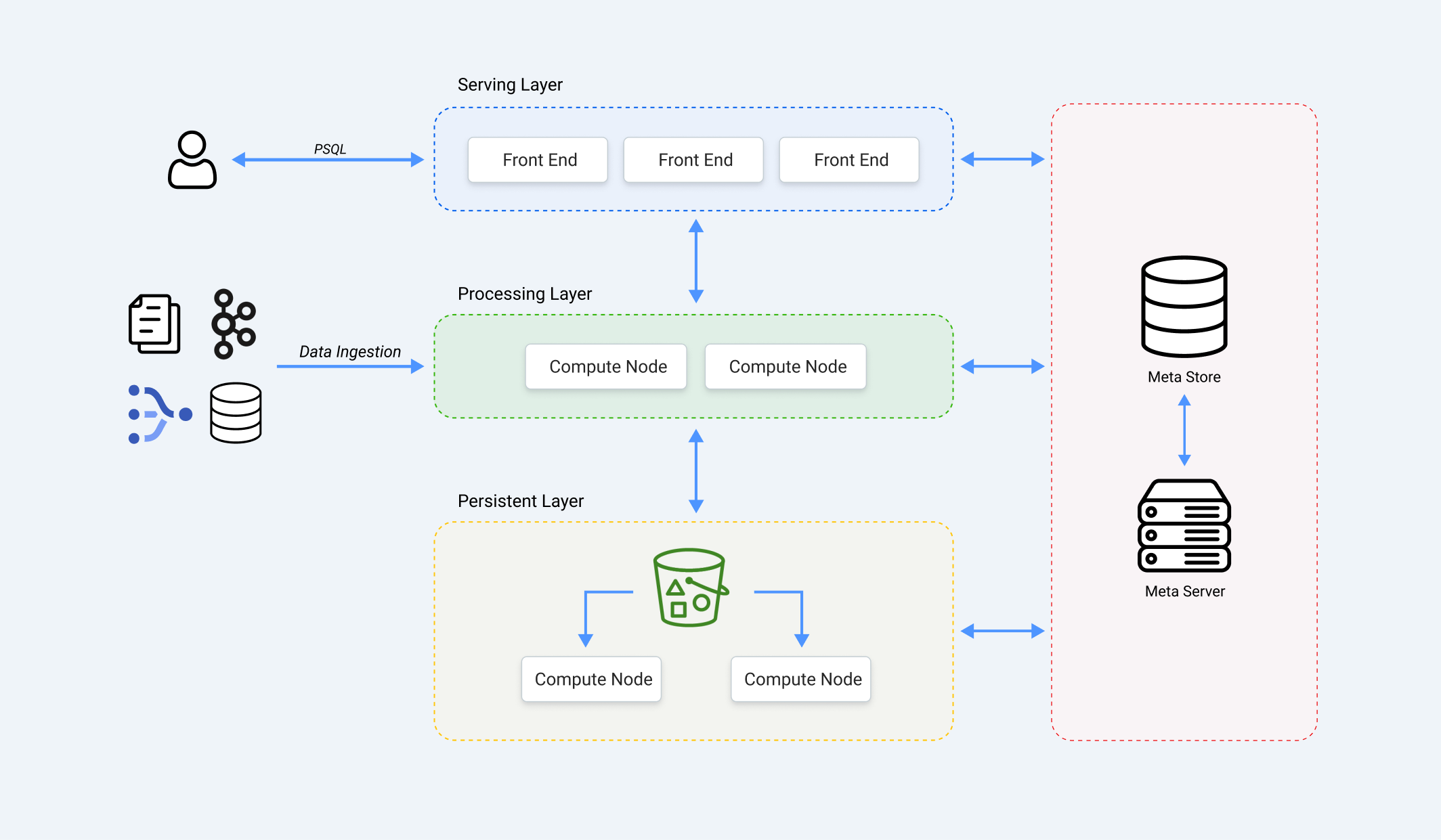
RisingWave follows a cloud-native design with stateless components, ensuring high availability and scalability. The persistent state is divided into two key parts:
Persistent Data Storage: This is where the actual data for your tables, materialized views, and the state of stream processing operations are stored. It uses an efficient LSM tree format and resides in a cloud object storage service like AWS S3.
Metadata Storage (Meta Store): This is where all the information about the data and the system itself is kept.
The meta store is responsible for:
Catalog and User Information: Details about databases, tables, users, and their permissions.
LSM Tree Metadata: Information about the structure and organization of the data in the persistent data storage.
Streaming Task Topology: A map of all the active stream processing tasks and how they are distributed across the compute nodes.
RisingWave’s meta server directly interacts with the meta store to manage essential functions such as:
Metadata Management: Creating, updating, and deleting objects within RisingWave.
Scheduling: Dynamically allocating resources and managing the execution of stream processing tasks on compute nodes.
Checkpoint Management: Ensuring data durability and enabling recovery from failures.
LSM Tree Maintenance: Optimizing data storage by scheduling and executing compaction tasks.
As we scaled, it became clear that the meta store's performance was crucial, and our initial choice of etcd started to show its limitations.
The etcd Era: Initial Success and Emerging Pains
Initially, RisingWave used etcd, a popular distributed key-value store, as its meta store. etcd was a good starting point because it's reliable, provides high availability, and supports transactions. However, as RisingWave gained adoption and users started deploying larger, more complex clusters, we began to encounter limitations with etcd.
Development Bottlenecks and the Cache Conundrum
etcd's simple key-value model presented significant challenges for our developers. For complex queries such as checking for circular dependencies in stream processing graphs, developers need to choose between:
A: Use multiple round trips to etcd, which degrades performance;
B: Implement a complex in-memory cache to mitigate performance issues, which introduces new challenges, such as maintaining consistency between the cache and etcd, leading to frustrating bugs and increased memory usage. We chose the latter approach, thus having to deal with the complexity and reliability challenges.
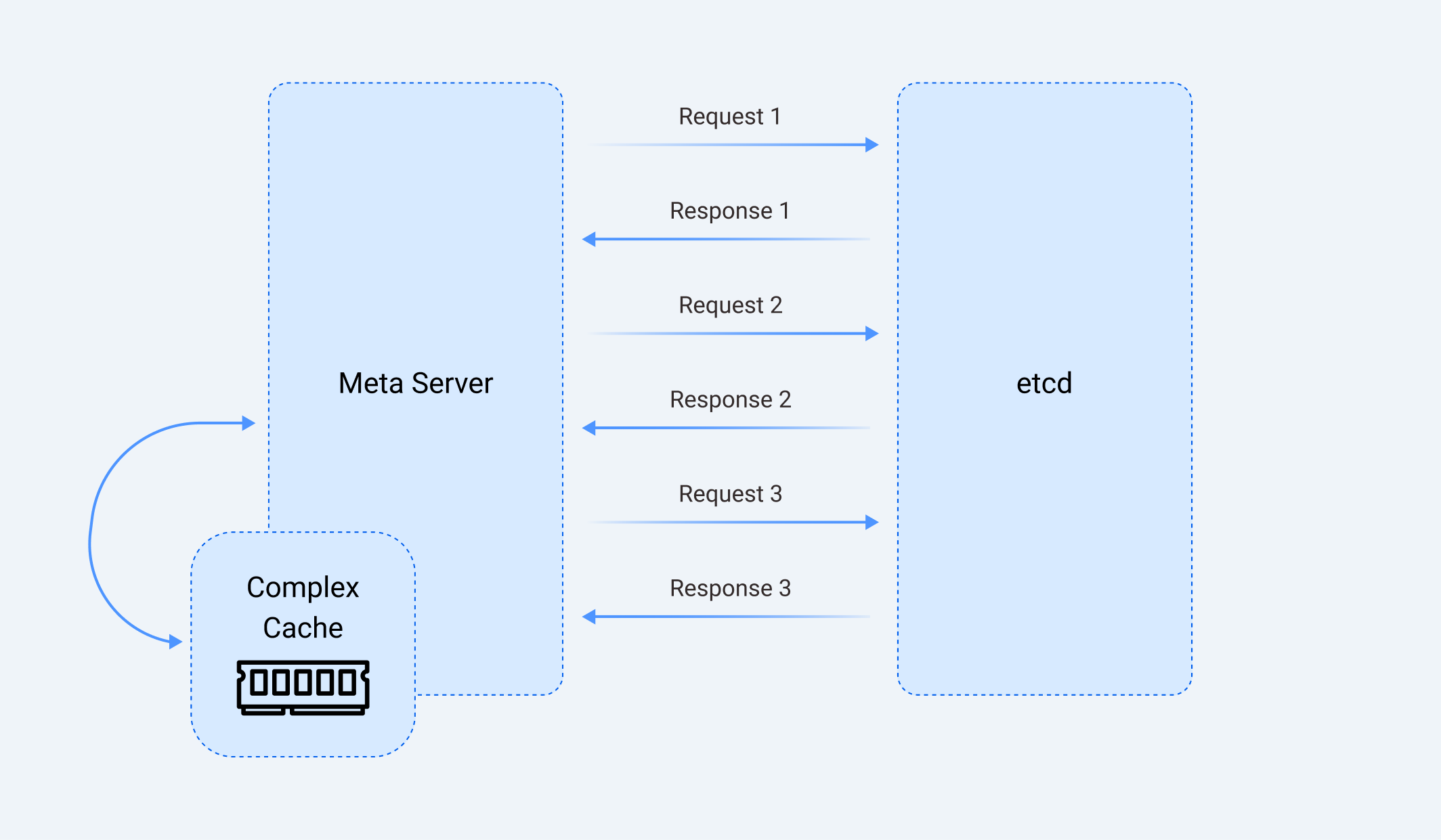
The Cloud-Native Nightmare: Managing etcd at Scale
Managing etcd in cloud environments turned into a deployment and management nightmare. There is no managed etcd service offered by major cloud providers, so we had to deploy and manage it ourselves. etcd is primarily designed for bare-metal deployments, and its performance often suffered in cloud environments due to the relatively slower disk performance compared to on-premise setups.
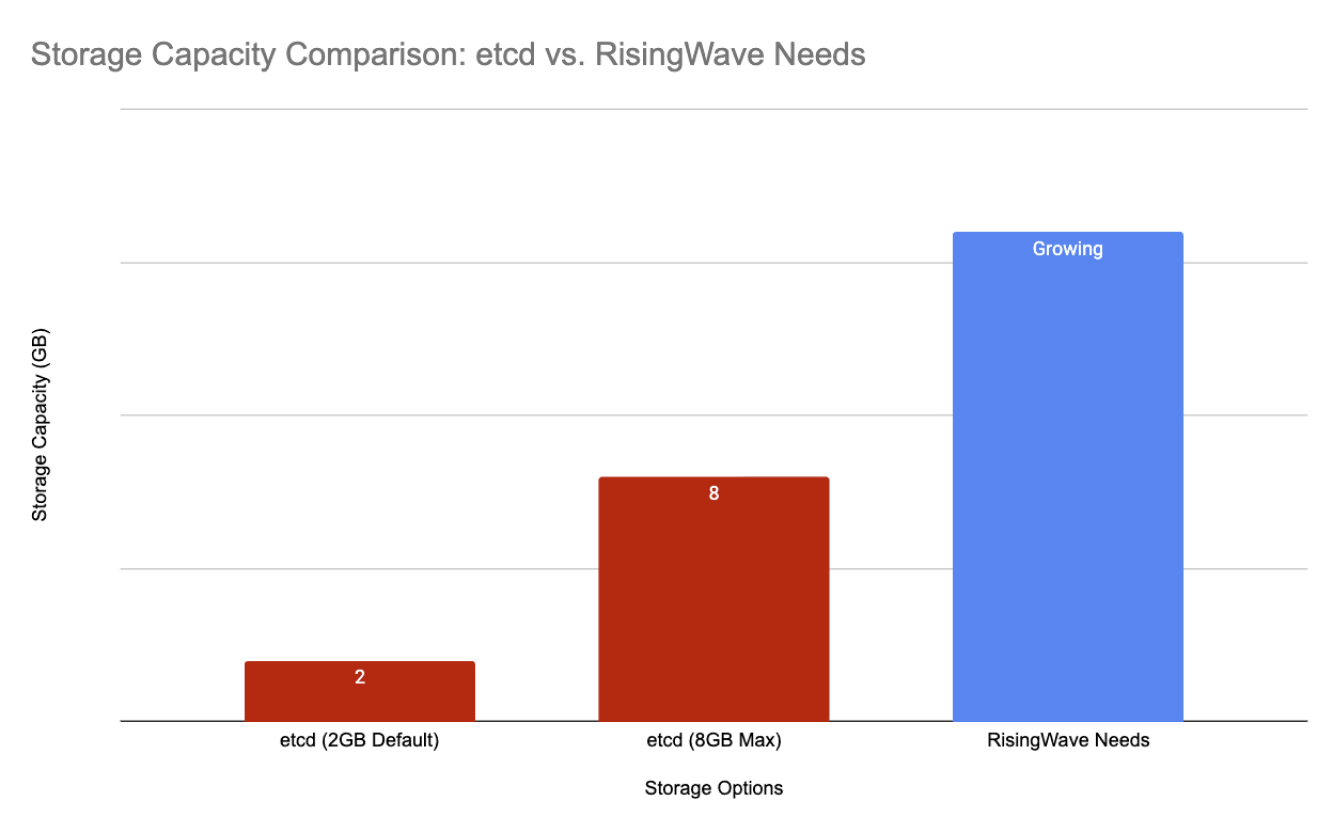
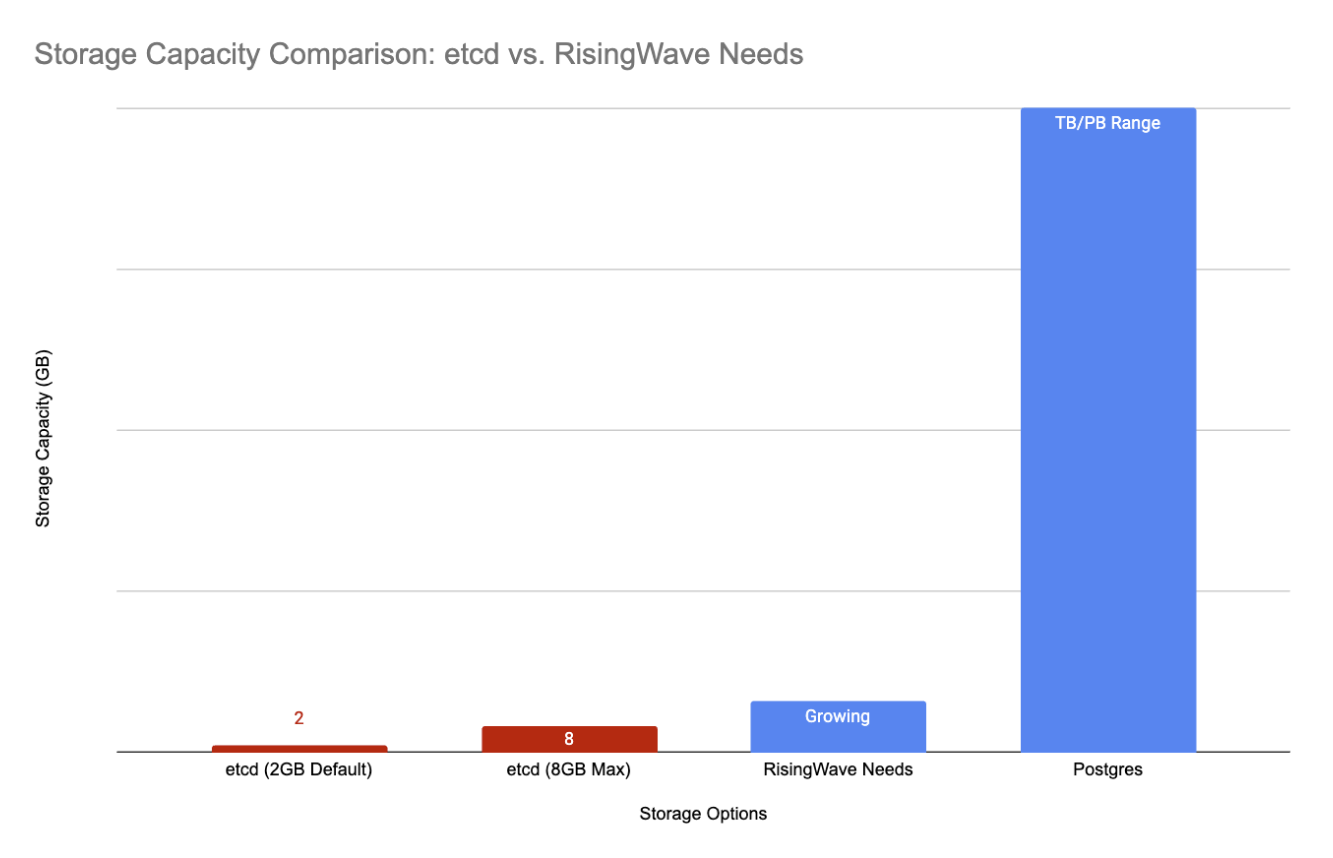
Hitting the Wall: etcd's Storage Limits and Data Corruption
etcd's architecture, based on a single Raft group without sharding, severely limits its scalability. The default storage limit is only 2GB, with a recommended maximum of 8GB. This was a major constraint for us, as the metadata volume in RisingWave clusters grew rapidly. In some cases, we even experienced data corruption due to partially committed transactions in etcd when disks ran out of space. The use of Protobuf encoding for metadata also made debugging and troubleshooting a complex ordeal.
The SQL Solution: Embracing the Power of Postgres
To overcome the limitations of etcd, we made a strategic decision to transition to a SQL-based backend for RisingWave's meta store, leveraging a robust OLTP database system: PostgreSQL. This move brings several advantages in terms of simplified development, streamlined cloud operations, and enhanced scalability.
Unlocking Developer Productivity with SQL
The SQL backend has significantly simplified the development process. We can now use the full power of SQL to query metadata, enabling us to perform complex operations with ease. For example, checking for circular dependencies in a stream processing graph, which required multiple round trips and complex caching logic with etcd, can now be done using a simple recursive CTE in SQL.
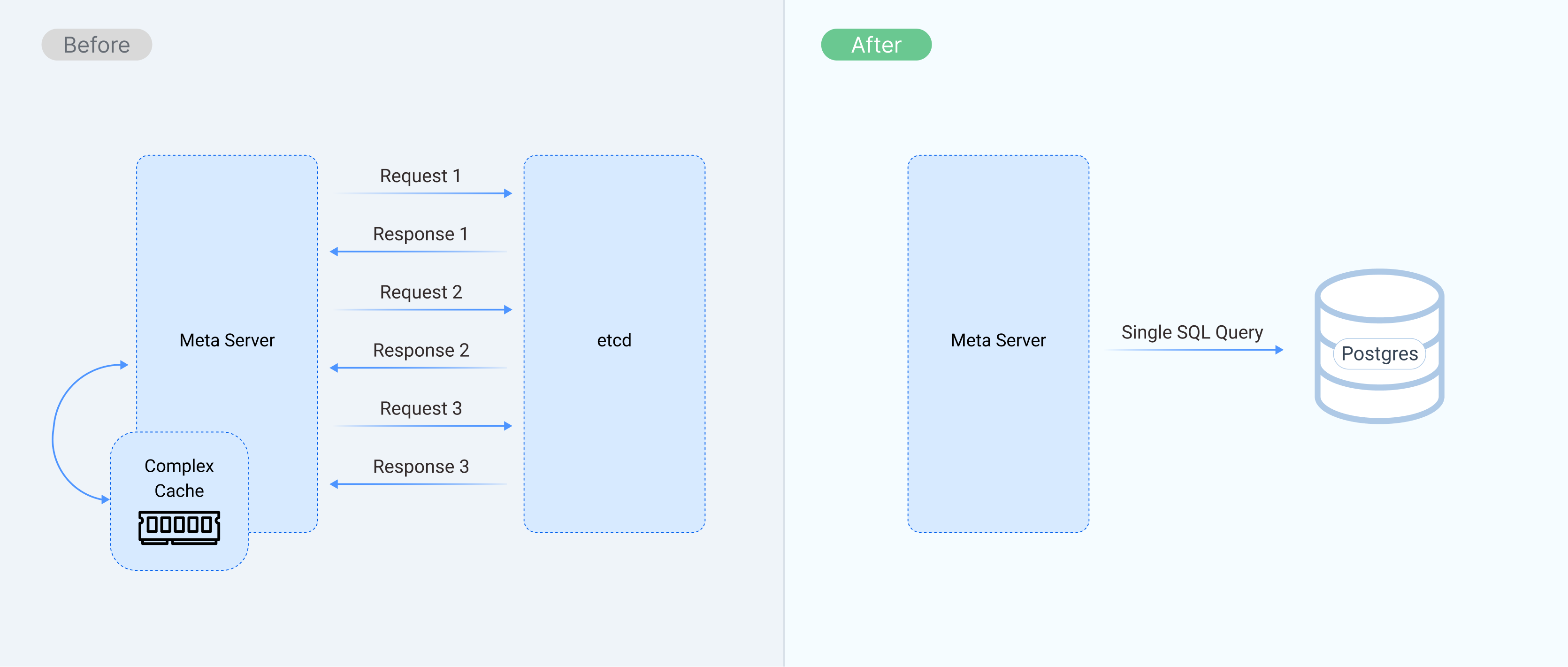
SQL databases support indexing, allowing for fast retrieval of metadata records. The powerful querying and indexing capabilities of SQL databases also eliminate the need for a complex in-memory cache in the meta server, simplifying the architecture and reducing memory consumption.
Cloud-Native Simplicity: Managed Postgres to the Rescue
Adopting a SQL backend has streamlined our cloud operations. We can now leverage fully managed relational database services like AWS RDS, Azure Database for PostgreSQL, and Google Cloud SQL. These services are highly optimized for performance and reliability, ensuring that the meta store can handle the demands of large-scale RisingWave deployments. This has drastically reduced our operational overhead, freeing up our engineers to focus on building new features rather than managing infrastructure.
Breaking the Limits: A Meta Store That Scales
The SQL backend has greatly enhanced the scalability and data capacity of RisingWave's meta store. Modern relational databases can handle terabytes of data, far exceeding the capacity of etcd. This allows RisingWave to support much larger and more complex deployments, giving us 10x more headroom for growth. A SQL backend also enables the possibility of sharing a single database instance among multiple RisingWave clusters.
Challenges, Trade-offs, and Lessons Learned
While the transition to a SQL backend has brought numerous benefits, it also presented some challenges and trade-offs.
Migration Challenges
One of the main challenges was ensuring a smooth migration for existing RisingWave users who were still using etcd. We had to develop a migration tool that could transfer the metadata from etcd to the SQL backend without causing any downtime or data loss.
Trade-offs
One potential trade-off is increased latency for certain metadata operations compared to etcd. etcd, being an in-memory key-value store, can offer lower latency for simple reads and writes. However, we found that for the majority of our use cases, the performance of the SQL backend was more than adequate. In addition, the added complexity of managing a SQL database compared to etcd is largely mitigated by using managed services.
The Migration Process
We developed a migration tool to help users transition from etcd to the SQL backend. For the detailed instructions, please see the migration guide.
Key Takeaways
This migration taught us the importance of choosing the right tool for the job, even if it means revisiting established technologies like SQL. It also highlighted the value of managed services in reducing operational burden and improving scalability.
Conclusion
Our journey from etcd to a Postgres-backed meta store was a significant undertaking, but it's been a game-changer for RisingWave. This change, officially supported as of RisingWave 2.1, represents a major step forward in RisingWave's evolution, enabling greater scalability, reliability, and ease of use. By embracing the power and maturity of SQL, we've not only overcome the limitations that were holding us back but also laid the foundation for a more scalable, reliable, and developer-friendly future. We're excited to see what our users will build with this enhanced platform.
Ready to experience the power of RisingWave? Get started today by visiting our website. Dive deeper into the code on our GitHub repository. Join our vibrant Slack community to connect with our engineers and other streaming enthusiasts! If you would like to stay up to date on what RisingWave is up to, sign up for our monthly newsletter. Follow us on Twitter and LinkedIn.